Nextcloud lässt sich sehr einfach mit Docker auf einem QNAP NAS installieren. In diesem Tutorial zeige ich dir, wie das geht.
Hardware
In meinem Fall handelt es sich um ein TS-233. Es sollte aber auch mit den meisten anderen QNAP NAS funktionieren. Es muss nur Container Station darauf laufen. Hier findest du die Systemanforderungen dafür: https://www.qnap.com/de-de/software/container-station
Installation von Container Station
Container Station ist die Docker-Umgebung von QNAP, in der wir später Nextcloud installieren werden. Diese kann einfach im App-Center installiert werden:
Beim ersten Start wird gefragt, wohin die Docker-Dateien gespeichert werden sollen. Ansonsten ist keine weitere Konfiguration mehr möglich.
Erstellen der Ordner
In der File Station müssen zwei weitere Ordner erstellt werden. Einen für die Konfigurationsdateien von Nextcloud und den anderen für die Nextcloud-Daten, also die Dateien, die der Nutzer später hochlädt.
Erstellen des Docker Containers
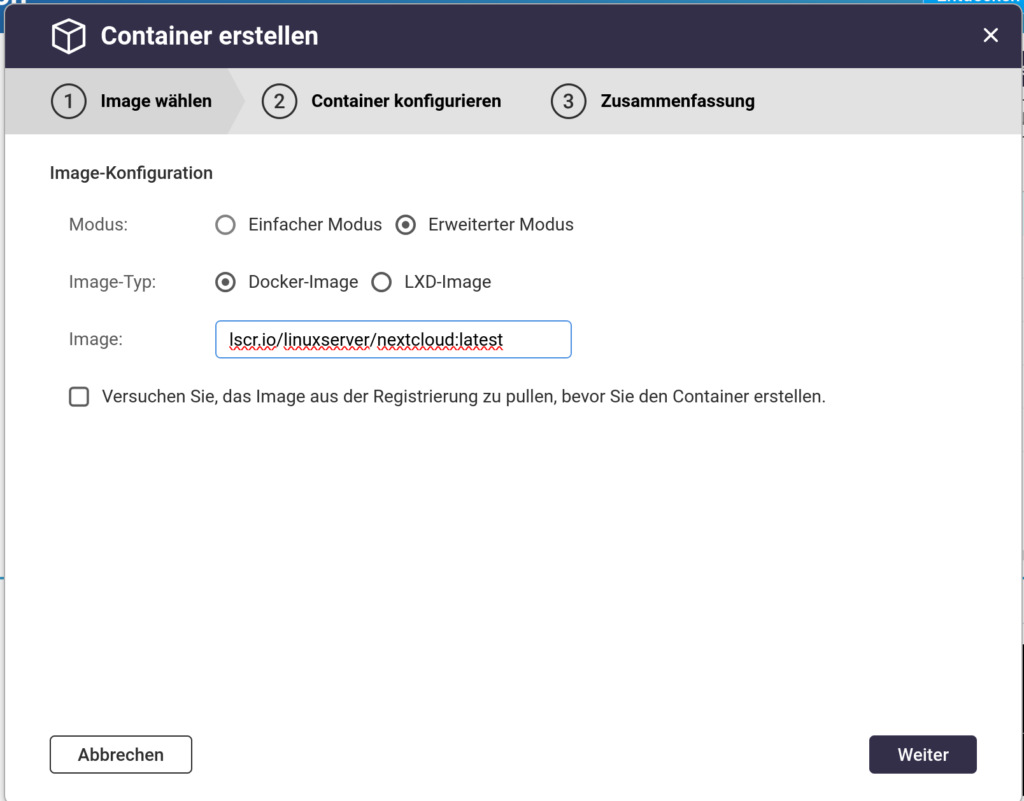
In der Container-Station wählen wir „Container“->“Erstellen“. Dort wählen wir den erweiterten Modus und als Image lscr.io/linuxserver/nextcloud:latest.
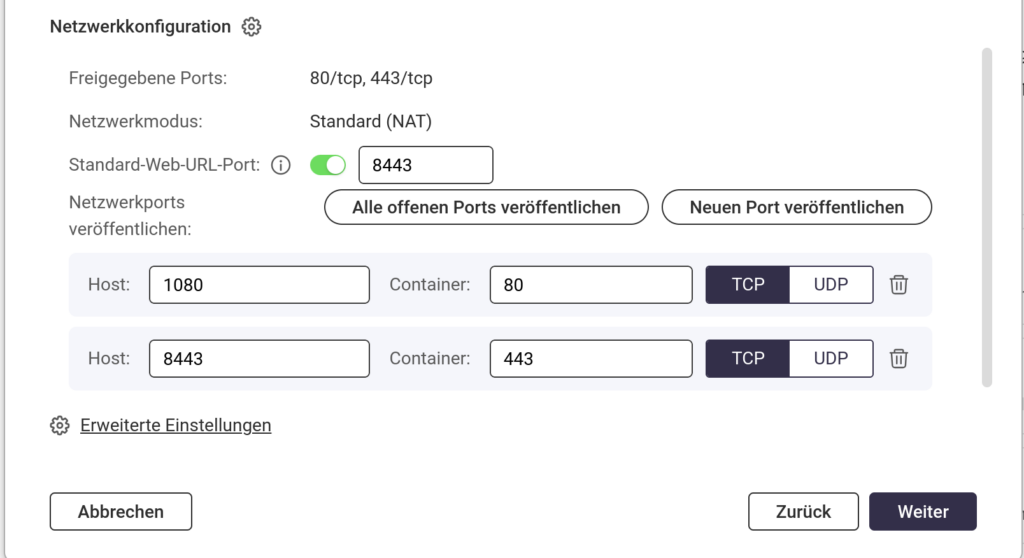
Als WebURL-Port wähle ich 8443. Ebenso für den Port 443 im Container. Für den Container-Port 80 wähle ich 1080.
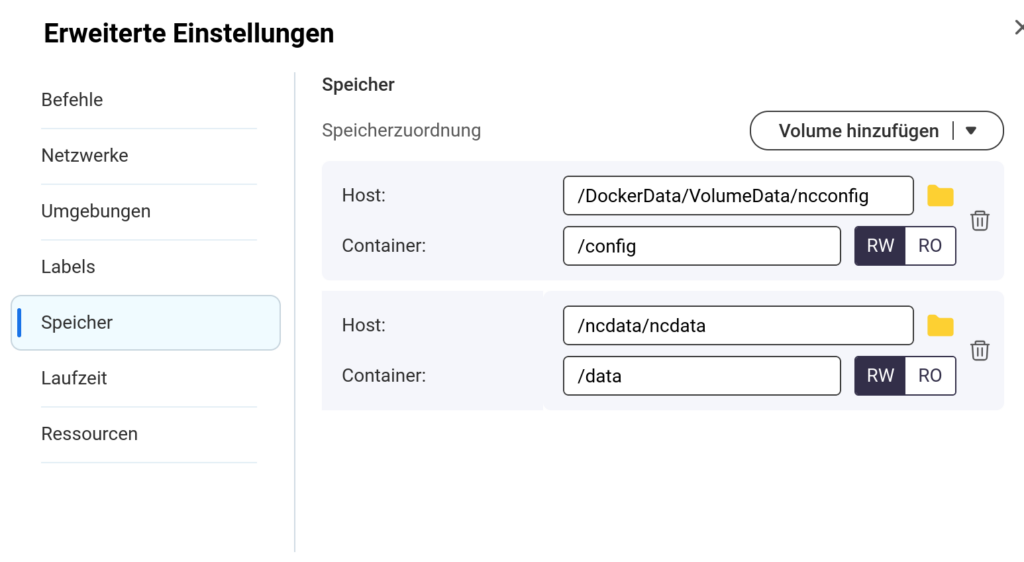
Anschließend wählen wir „Erweiterte Einstellungen“.
Dort müssen wir 2 Volumes („Mount-Host-Pfad“) anlegen. Eines für die Config-Dateien (/config im Container) und eines für die Daten (/data im Container).
Das wars auch schon. Der Container kann jetzt erstellt werden. Das Webinterface von Nextcloud ist jetzt unter https://IP_DEINES_NAS:8443 erreichbar. Hier muss man nur noch das Admin-Konto anlegen.
Seit gut drei Jahren betreibe ich einen RaspberryPi als Homeserver. Zunächst reichte dieser noch gut aus. Mit der Zeit wurde aber nicht nur die Zahl der Anwendungen, die auf dem Raspberry laufen, mehr, sondern auch die Leistungsanforderungen der Anwendungen selbst. Besonders meine ich damit die Influx Datenbank, die seit über drei Jahren jede Minuten um einen Datensatz der PV-Anlage größer wird. Die Datenbank braucht mittlerweile über 10 Minuten zum Starten. Auch diese Webseite braucht zum Laden deutlich länger, als sie sollte. Wenn ich den Raspberry komplett neu starte, braucht es ca. eine Stunde, bis alle Anwendungen wieder laufen. Das ist definitiv zu viel. Es sollte also ein neuer Rechner her. In dieser Artikelserie möchte ich davon berichten.
Zum Abschluss dieser Serie möchte ich noch ein paar Worte über den Stromverbrauch verlieren. Diesen habe ich über mehrere Wochen mit einer Shelly Plug S gemessen. Das Ergebnis: Im „Leerlauf“ braucht der Server inklusiv zweier Festplatten ca. 20-25W. Mit Leerlauf meine ich hier keinen Leerlauf im Sinne von „Der Server macht nichts“, sondern ich meine den Zustand, den der Server hat, wenn man gerade nicht aktiv auf ihn zugreift, z. B. durch Hochladen von Dateien oder durch großen Datenverkehr übers VPN. Es laufen also natürlich trotzdem einige Dienste, die Leistung brauchen.
Auf das Jahr hochgerechnet macht das 0,0225kW × 24h × 365 = 197,1 kWh im Jahr. Das sind je nach Strompreis knapp 70 € im Jahr oder 6 € im Monat.
Seit gut drei Jahren betreibe ich einen RaspberryPi als Homeserver. Zunächst reichte dieser noch gut aus. Mit der Zeit wurde aber nicht nur die Zahl der Anwendungen, die auf dem Raspberry laufen, mehr, sondern auch die Leistungsanforderungen der Anwendungen selbst. Besonders meine ich damit die Influx Datenbank, die seit über drei Jahren jede Minuten um einen Datensatz der PV-Anlage größer wird. Die Datenbank braucht mittlerweile über 10 Minuten zum Starten. Auch diese Webseite braucht zum Laden deutlich länger, als sie sollte. Wenn ich den Raspberry komplett neu starte, braucht es ca. eine Stunde, bis alle Anwendungen wieder laufen. Das ist definitiv zu viel. Es sollte also ein neuer Rechner her. In dieser Artikelserie möchte ich davon berichten.
Kennt ihr Google Fotos? Das ist ein Programm von Google, um seine Fotos zu verwalten. Die Fotos vom Smartphone werden mit der Cloud synchronisiert und sind dann auf allen Geräten, auf denen man mit seinem Google Account angemeldet ist, synchronisiert. Man bekommt ab und zu ganz nette Rückblicke („Schau dir an, was du vor X Jahren gemacht hast …“) und man kann „intelligent“ nach Dingen suchen, die auf den Fotos zu sehen sind.
Google Fotos finde ich sowohl optisch als auch von den Funktionen her sehr ansprechend. Wären da nicht zwei kleine (eher eine kleine und eine sehr große) Sachen, die mich stören würden. Das für mich kleinere Problem ist, dass meine privaten Fotos auf Google Servern liegen. Das stört mich jetzt vielleicht weniger als so manch anderen, aber wenn die Fotos bei mir bleiben würden, fände ich das schon besser. Das viel größere Problem ist aber der begrenzte Speicherplatz. Mit 15 GB gehört Google zwar zu den Cloudanbietern, die im kostenlosen Programm am meisten Speicherplatz bieten. Nach ein paar Jahren wird das aber für Fotos einfach zu wenig.
Deswegen machte ich mich auf die Suche nach einer selbst gehosteten Alternative und bin auf Immich gestoßen. Als ich die Oberfläche gesehen habe, war ich echt begeistert. Diese ist nahezu identisch zur Oberfläche von Google Fotos. Auch der Funktionsumfang ist ähnlich. Damals habe ich noch versucht, Immich auf einem RaspberryPi zu installieren. Grundsätzlich möglich, man sollte aber dann auf die Objekt- und Personenerkennungsfunktionen verzichten. Das zieht einfach zu viel CPU-Last, bzw. wenn man seine bestehenden Fotos importiert, wird man nie fertig, da die Objekterkennung für die paar tausend Fotos VIEL zu lange braucht. Da ich mir aber einen neuen Server mit mehr Leistung angeschafft habe, sollte das auf diesem um einiges besser laufen.
Kurze Info vorweg: Die Entwickler von Immich weisen auf ihrer Webseite auf die schnelle Entwicklung hin. Immich sollte nicht die einzige Methode sein, seine Fotos zu speichern.
Installation
Die Dokumentation bietet viele Installationsmöglichkeiten an. Ein Installationsskript, Docker und sogar Unraid sind dabei. Da ich bereits eine Portainer-Instanz bei mir am Laufen habe, wähle ich diese Methode.
Da die Installation in der Dokumentation sehr gut erklärt ist, gehe ich an dieser Stelle nicht weiter darauf ein.
Erste Einrichtung
Zunächst kam bei mir die Fehlermeldung, dass Immich keinen Zugriff auf die Datenbank hätte. Das lag daran, dass diese einfach noch nicht fertig gestartet war. Nach kurzer Wartezeit wurde ich dann schon vom schlichten Willkommens-Screen begrüßt:
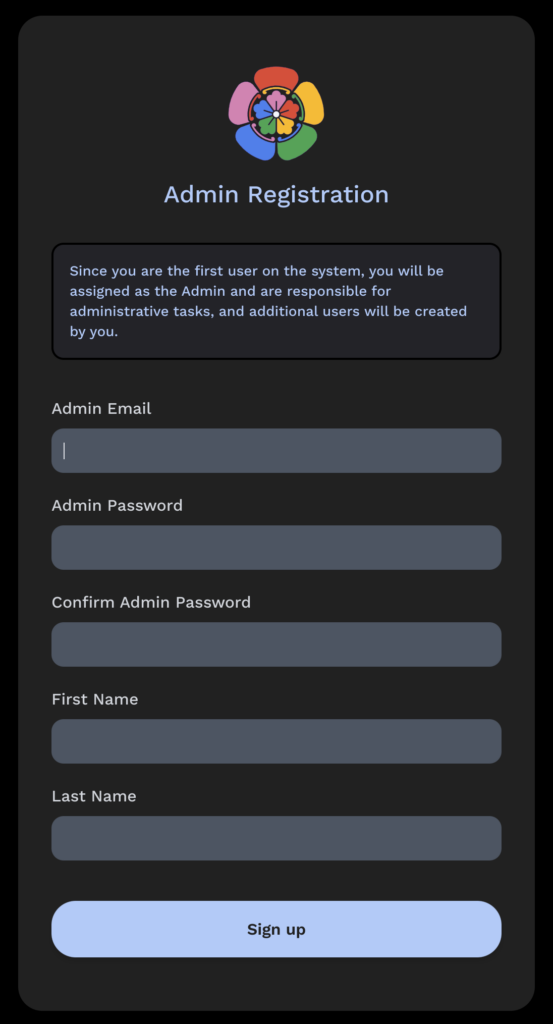
Anschließend kann man einen Admin-Account erstellen:
Oberfläche
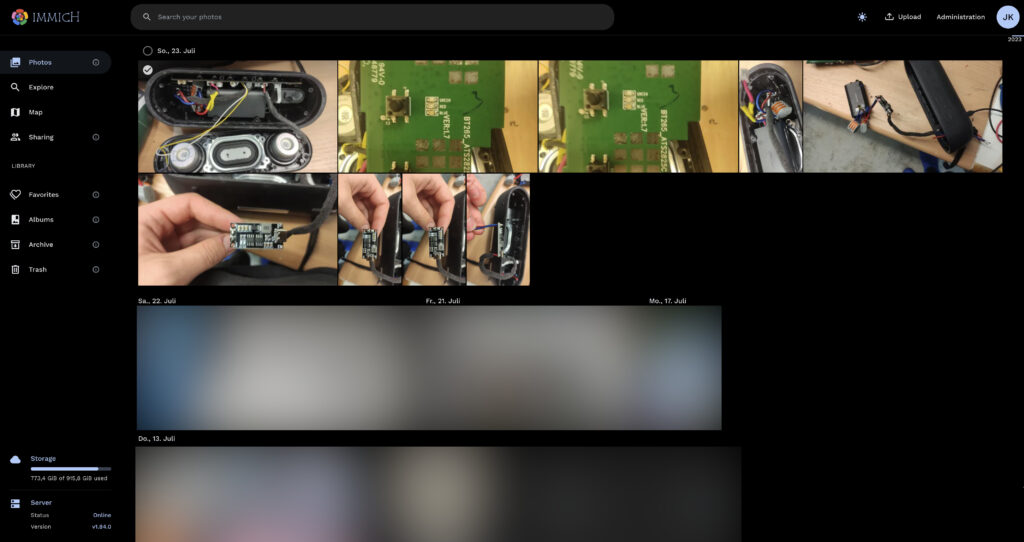
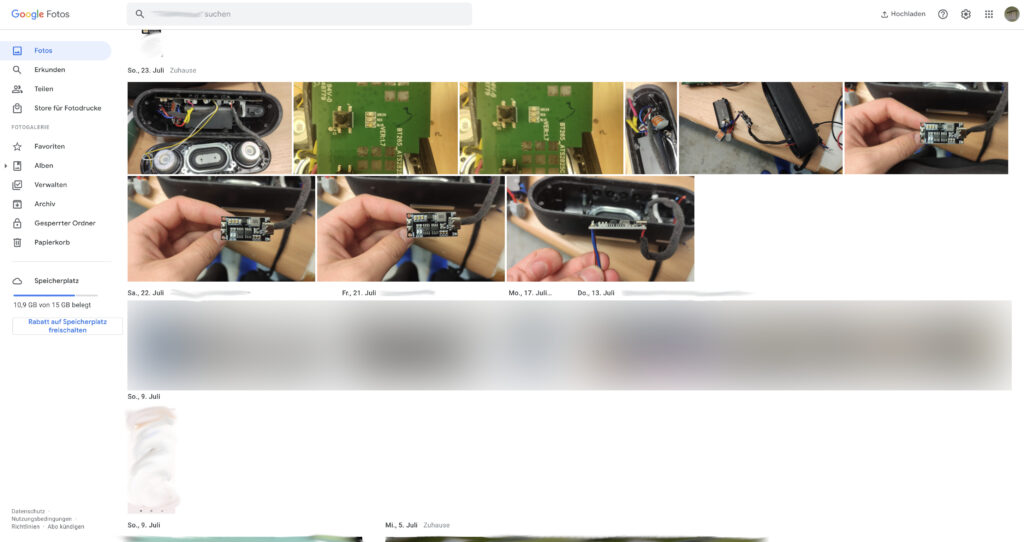
Wie schon gesagt, ist die Oberfläche von Immich nahezu identisch zu der von Google Fotos. Hier mal ein paar Vergleiche:
Startseite von ImmichStartseite von Google Fotos„Erinnerungen“ in Immmich„Erinnerungen“ in Google Fotos
Seit gut drei Jahren betreibe ich einen RaspberryPi als Homeserver. Zunächst reichte dieser noch gut aus. Mit der Zeit wurde aber nicht nur die Zahl der Anwendungen, die auf dem Raspberry laufen, mehr, sondern auch die Leistungsanforderungen der Anwendungen selbst. Besonders meine ich damit die Influx Datenbank, die seit über drei Jahren jede Minuten um einen Datensatz der PV-Anlage größer wird. Die Datenbank braucht mittlerweile über 10 Minuten zum Starten. Auch diese Webseite braucht zum Laden deutlich länger, als sie sollte. Wenn ich den Raspberry komplett neu starte, braucht es ca. eine Stunde, bis alle Anwendungen wieder laufen. Das ist definitiv zu viel. Es sollte also ein neuer Rechner her. In dieser Artikelserie möchte ich davon berichten.
WireGuard ist eine Software, um eine VPN-Verbindung aufzubauen. Sie ist im Vergleich zu anderen, wie zum Beispiel OpenVPN schneller und einfacher.
Installation von WireGuard
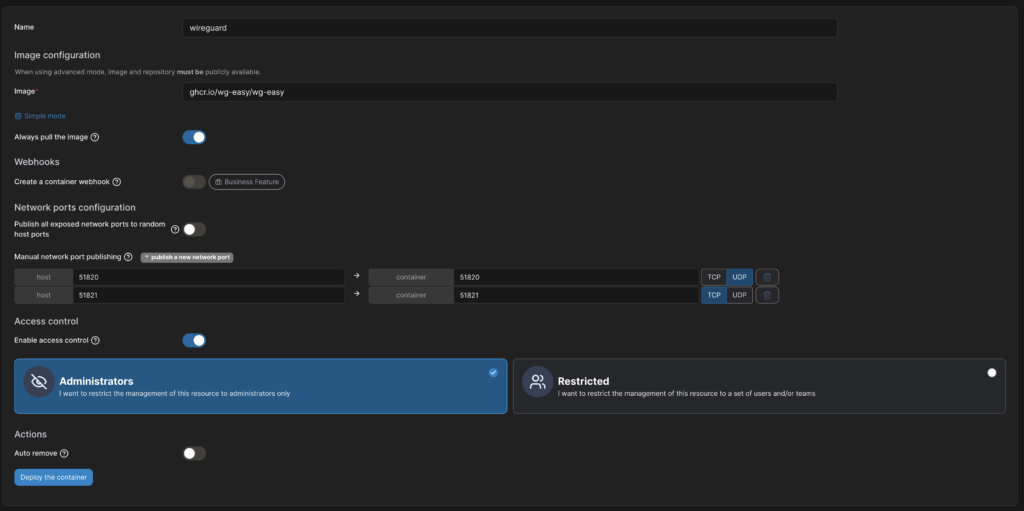
WireGuard selbst ist bereits in den Linux-Kernel integriert. Eine schöne Möglichkeit, Verbindungen einfach zu verwalten, aber nicht. Hier hilft uns das Tool „wg-easy„. Damit lassen sich WireGuard-Verbindungen wirklich sehr einfach verwalten. Wg-easy wird im Docker-Container installiert. Dazu erstelle ich einen neuen Container in Portainer, gebe ihm den Namen „Wireguard“ und wähle das Image „ghcr.io/wg-easy/wg-easy:latest“ im Advanced Mode. Außerdem gebe ich den Port 51820 über UDP und den Port 51821 über TCP frei. Letzteres wird später der Port für das Webinterface sein.
Anschließend erstelle ich ein Volume für die Konfigurationsdateien:
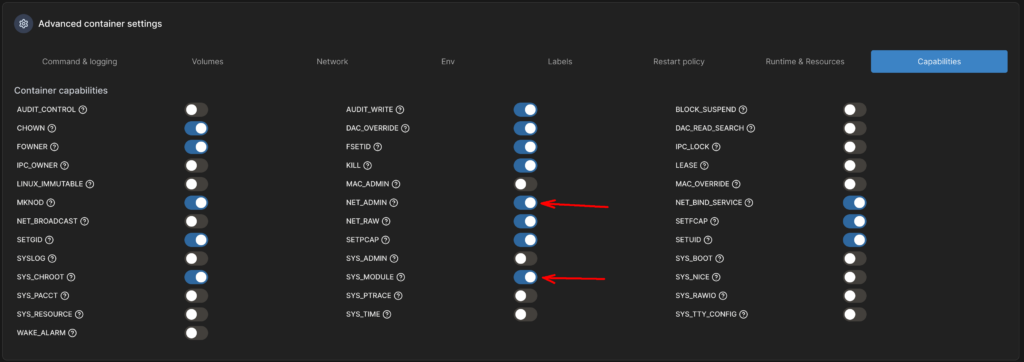
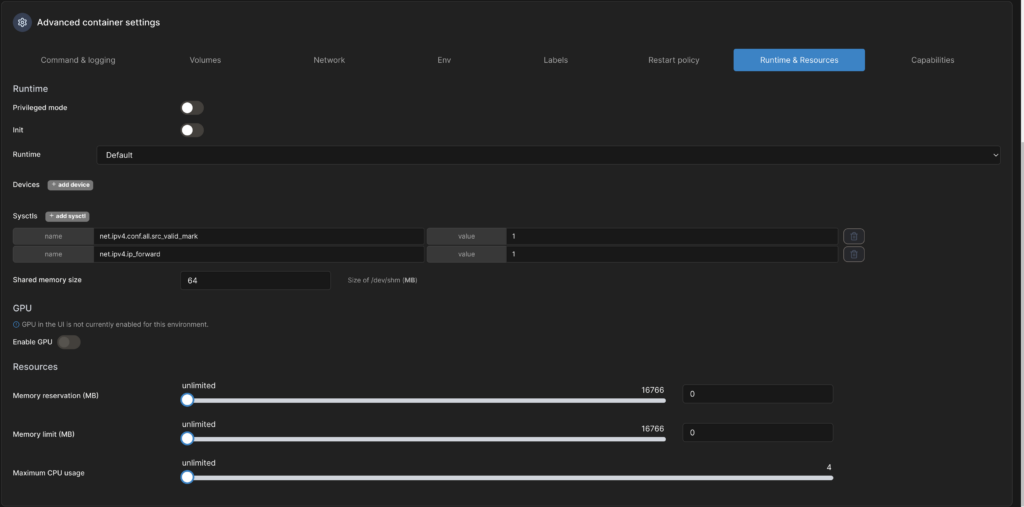
Da WireGuard einige zusätzliche Berechtigungen braucht, ist die Konfiguration dieses Containers etwas komplizierter als die der Container, die wir bisher in dieser Artikelserie hatten. Unter „Capabilities“ muss man die Optionen „NET_ADMIN“ und „SYS_MODULE“ aktivieren.
Zudem müssen im Menü „Runtime & Ressources“ die Sysctls net.ipv4.conf.all.src_valid_mark und net.ipv4.ip_forward jeweils mit dem Wert „1“ hinzugefügt werden.
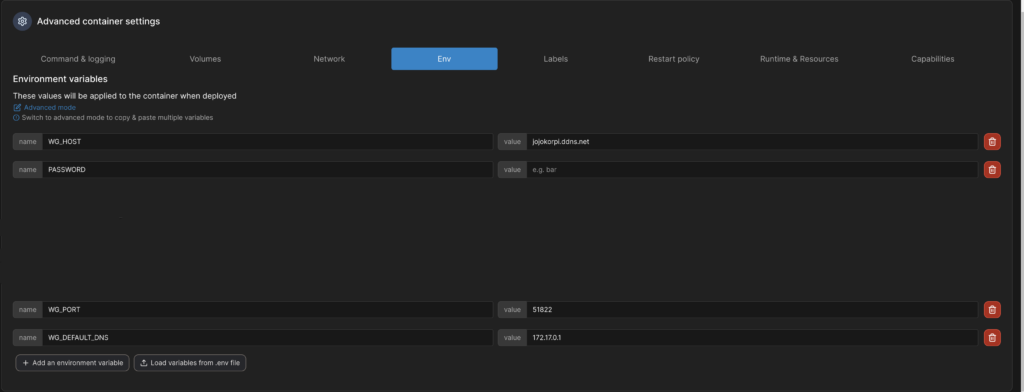
Im letzten Schritt füge ich noch Umgebungsvariablen hinzu. Eine vollständige Liste der möglichen Variablen findet man im Git-Repository von wg-easy. Ich verwende die Einstellungen PASSWORD, um das Passwort für das Webinterface festzulegen, WG_HOST, um den Hostname des VPN-Servers festzulegen (Der Hostname, unter dem der Server von außerhalb des Heimnetzwerks erreichbar ist), WG_PORT, um den Port von außerhalb festzulegen (Wer aufmerksam war, hat erkannt, dass das nicht der Port ist, unter dem der VPN-Server innerhalb meines Heimnetzwerks erreichbar ist.) und WG_DEFAULT_DNS. Das ist der DNS-Server, den die VPN-Clients standardmäßig verwenden. In meinem Fall ist das die IP meines Servers innerhalb des Docker-Netzwerkes. Das führt dann dazu, dass alle VPN-Clients automatisch mein Pihole verwenden.
Nachdem der Container erstellt ist, erreicht man das Webinterface unter dem vorher angegebenen Port.
Erstellen einer VPN-Verbindung
Im Webinterface muss man anschließend sein vorher festgelegtes Passwort eingeben.
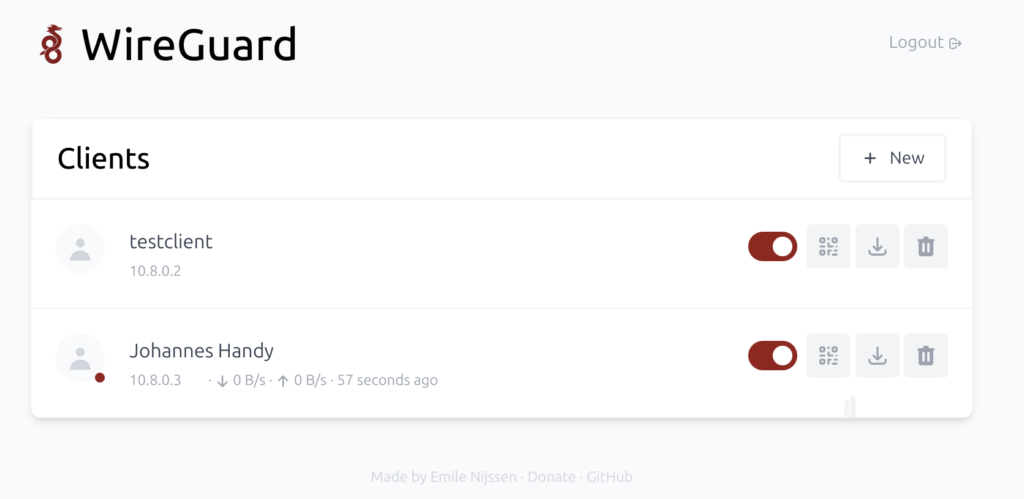
Dann kann man mit „New“ eine Konfiguration für einen neuen VPN-Client anlegen. Dabei muss man nur den Namen eingeben und schon erscheint der Client in der Liste.
Es gibt nun zwei Möglichkeiten, die Konfiguration auf den Client zu laden. Entweder man klickt auf den QR-Code, den man dann mit der WireGuard-App scannen kann, oder man lädt die Konfigurationsdatei herunter.
Seit gut drei Jahren betreibe ich einen RaspberryPi als Homeserver. Zunächst reichte dieser noch gut aus. Mit der Zeit wurde aber nicht nur die Zahl der Anwendungen, die auf dem Raspberry laufen, mehr, sondern auch die Leistungsanforderungen der Anwendungen selbst. Besonders meine ich damit die Influx Datenbank, die seit über drei Jahren jede Minuten um einen Datensatz der PV-Anlage größer wird. Die Datenbank braucht mittlerweile über 10 Minuten zum Starten. Auch diese Webseite braucht zum Laden deutlich länger, als sie sollte. Wenn ich den Raspberry komplett neu starte, braucht es ca. eine Stunde, bis alle Anwendungen wieder laufen. Das ist definitiv zu viel. Es sollte also ein neuer Rechner her. In dieser Artikelserie möchte ich davon berichten.
MQTT ist ein Übertragungsprotokoll, das besonders Anwendung im IoT-Bereich findet. Dabei gibt es eine Zentrale, den Broker. Möchte man als Client etwas senden, so sendet man diese Nachricht unter einem Topic zuerst an den Broker. Das nennt man dann publish. Möchte man als Client etwas empfangen, so kann man bestimmte topics beim Broker abonnieren. Das nennt man subscribe. Das hat den Vorteil, dass Sender und Empfänger sich nicht kennen müssen, sondern nur jeweils den Broker. Die Topics sind mit „/“ aufgebaut, zum Beispiel „sensoren/küche/raumtemperatur“. Wenn man jetzt „sensoren/#“ subscribed („#“ steht für „alles“), dann bekommt man die Daten aller Sensoren. Subscribed man „sensoren/küche/#“, dann nur die der Sensoren in der Küche, usw.
Was ist Mosquitto?
Mosquitto bietet sowohl einen Client, um auf einen MQTT Server zuzugreifen, als auch den MQTT Server selbst. In diesem Beitrag soll es hauptsächlich um den Server gehen.
Installation von Mosquitto
Mosquitto lässt sich recht einfach im Terminal installieren mit:
1
sudo apt install mosquitto mosquitto-clients
Konfiguration von Mosquitto
Damit man auch aus dem Netzwerk auf den Server zugreifen kann, muss man noch eine kleine Einstellung vornehmen. Dazu erstellt man die Datei /etc/mosquitto/conf.d/mosquitto.conf:
1
sudo nano/etc/mosquitto/conf.d/mosquitto.conf
Und fügt dort folgendes ein:
1
2
allow_anonymous true
listener18830.0.0.0
Um die Einstellungen zu übernehmen, muss man den Mosquitto-Server noch neu starten:
1
sudo service mosquitto restart
Testen
Möchte man den Server ausprobieren, kann man das zum Beispiel mit einem weiteren Linux-Rechner tun. Dazu installiert man zuerst den Mosquitto Client:
1
sudo apt install mosquitto-clients
Mit folgendem Befehl lässt sich etwas auf dem Broker subscriben:
1
mosquitto_sub-h192.168.178.203-v-t"#"
Die IP-Adresse musst du natürlich anpassen. „-v“ sorgt dafür, dass nicht nur der Inhalt der Nachricht, sondern auch das Topic angezeigt wird. Hinter dem „-t“ steht in Anführungszeichen das Topic, das man subscriben möchte. „#“ steht für alles.
Mit folgendem Befehl lässt sich eine Nachricht senden:
Seit gut drei Jahren betreibe ich einen RaspberryPi als Homeserver. Zunächst reichte dieser noch gut aus. Mit der Zeit wurde aber nicht nur die Zahl der Anwendungen, die auf dem Raspberry laufen, mehr, sondern auch die Leistungsanforderungen der Anwendungen selbst. Besonders meine ich damit die Influx Datenbank, die seit über drei Jahren jede Minuten um einen Datensatz der PV-Anlage größer wird. Die Datenbank braucht mittlerweile über 10 Minuten zum Starten. Auch diese Webseite braucht zum Laden deutlich länger, als sie sollte. Wenn ich den Raspberry komplett neu starte, braucht es ca. eine Stunde, bis alle Anwendungen wieder laufen. Das ist definitiv zu viel. Es sollte also ein neuer Rechner her. In dieser Artikelserie möchte ich davon berichten.
Homeassistant ist eine Software zur Steuerung, Visualisierung und Automatisierung eines Smarthomes. In Homeassistant lassen sich Produkte von über 2500 Marken einbinden. Diese kann man dann zentral steuern oder automatisieren.
Installationsmethoden von Homeassistant
Grundlegend gibt es 3 Möglichkeiten, Homeassistant zu installieren: als „Homeassistant OS“, im Docker-Container oder direkt.
Homeassistant OS ist, wie der Name schon sagt, ein ganzes OS, also ein Linux-System mit Homeassistant (das übrigens auch hier in Docker installiert ist), Docker und einer vereinfachten Oberfläche, um weitere Docker-Container zu installieren. Praktisch Portainer nur sehr abgespeckt und mit begrenzter Auswahl an Containern. Die Vorteile dieser Installationsmethode sind, dass sie recht einfach ist und man auch als Anfänger recht leicht weitere Software installieren kann. Die Nachteile sind, dass man durch diese abgespeckte Software auch sehr beschränkt ist, vor allem, wenn man Homeassistant OS direkt installiert, da es eben ein ganzes OS ist und so keine weiteren Betriebssysteme parallel installiert werden können. Installiert man es aber in einer VM, zum Beispiel mit Proxmox, fällt dieser Nachteil natürlich weg. Aber auch dann braucht das Homeassistant OS minimal mehr Leistung als bei den anderen beiden Installationsmethoden.
Homeassistant im Docker-Container hat im Gegensatz zu Homeassistant OS eben nicht diese einfache Möglichkeit, andere Software zu installieren. Auch die Installation ist etwas komplizierter. Dafür hat man aber die volle Freiheit in der Wahl des Betriebssystems, unter dem Docker läuft und damit auch mehr Auswahl an Software.
Die direkte Installation von „Homeassistant core“ benötigt kein Docker. Der Funktionsumfang ist aber identisch zur Dockerinstallation. Der große Nachteil hier ist aber, dass die Installation mit Abstand am schwierigsten ist, da man sich hier mit verschiedenen Python-Versionen und Modulen herumschlagen muss.
Eine Übersicht der Installationsmethoden findet man hier.
Installation von Homeassistant
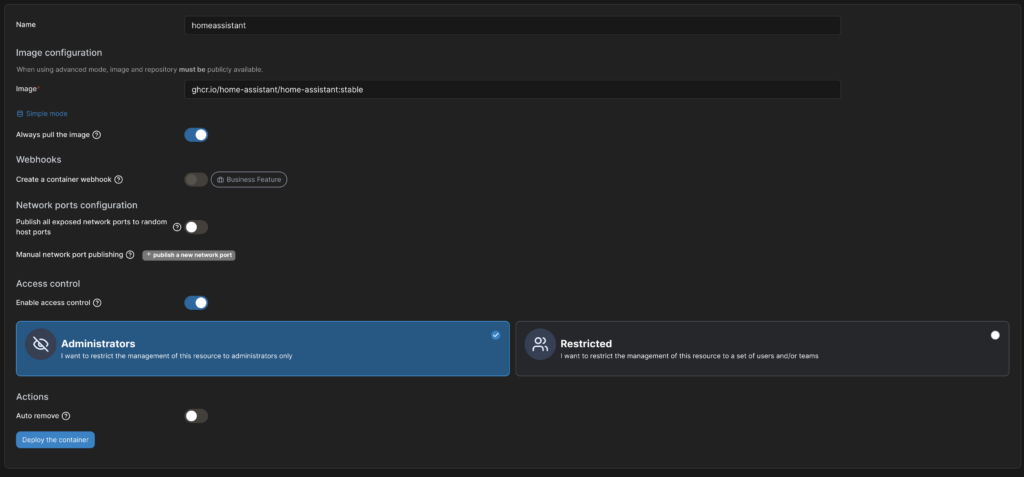
Ich habe mich für die Dockerinstallation entschieden. Dazu lege ich in Portainer einen neuen Container an. Diesen nenne ich „homeassistant“ und wähle im „Advanced mode“ das Image „ghcr.io/home-assistant/home-assistant:stable“.
Im Menü „Network“ wähle ich die Methode „host“.
Anschließend lege ich unter „env“ eine neue Umgebungsvariable für die Zeitzone an:
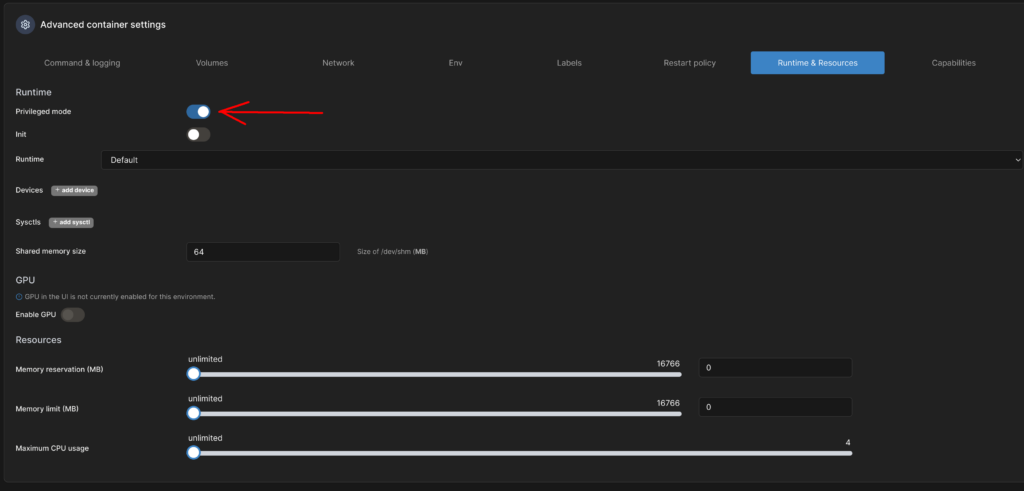
Dann aktiviere ich unter „Runtime & Resources“ den Priviledged Mode.
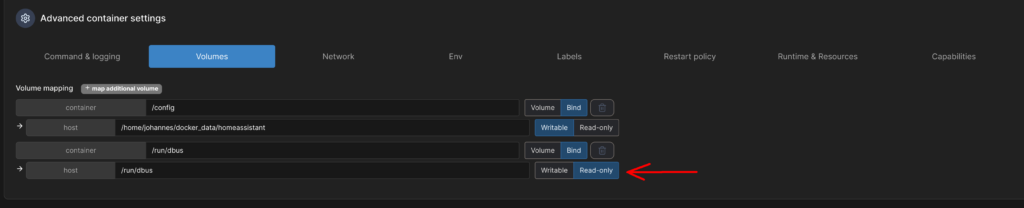
Als Letztes erstelle ich noch zwei Bind-Volumes. Beim ersten musst du den Pfad im Host bei deiner Installation anpassen. Beim zweiten ist es wichtig, dass er Read-Only gemountet ist.
Jetzt lässt sich der Container erstellen und anschließend die Weboberfläche von Homeassistant unter https://IP_ADRESSE:8123 öffnen.
Einrichten von Homeassistant
Dort begrüßt uns auch schon der Einrichtungsassistent:
Im ersten Schritt legt man einen Adminaccount an:
Anschließend legt man seine Heimatadresse fest, die zum Beispiel für die Wettervorhersage oder für Geofencing verwendet wird.
Für die Einheiten muss noch das Land festgelegt werden.
Möchte man anonyme Diagnosedaten an die Entwickler senden, kann man das im nächsten Schritt aktivieren:
Homeassistant sucht automatisch nach Geräten im Heimnetzwerk. Möchte man diese bereits bei der Einrichtung hinzufügen, kann man das mit einem Klick auf das jeweilige Gerät tun.
Installation von HACS
Homeassistant selbst bietet schon extrem viele Erweiterungen an. Noch mehr bekommt man mit dem „Home Assistant Community Store“ kurz HACS. Hier gibt es auch Erweiterungen für das Dashboard, zum Beispiel ein Wetterradar oder eine Erweiterung, um das Design des Dashboards per CSS zu ändern.
Um HACS zu installieren, geht man ins Terminal und wechselt in das Konfigurationsverzeichnis von Homeassistant. Das ist das Verzeichnis, wo auch unter anderem die Datei „configuration.yaml“ liegt.
Dort gibt man folgenden Befehl ein:
wget -O - https://get.hacs.xyz | bash -
Anschließend startet man Homeassistant neu, indem man unten links die Entwicklerwerkzeuge öffnet und dort auf „Neu starten“ klickt:
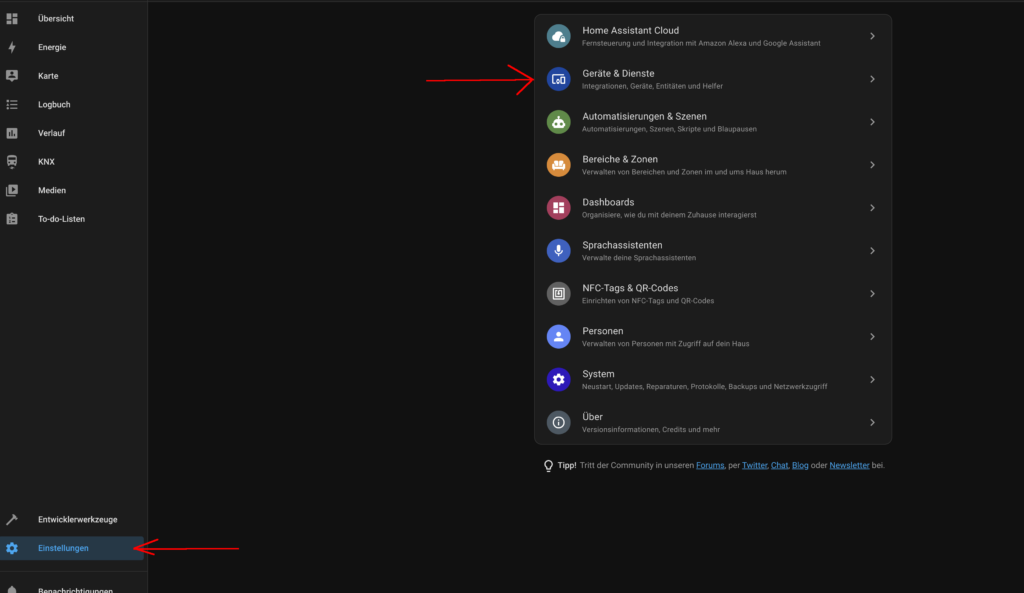
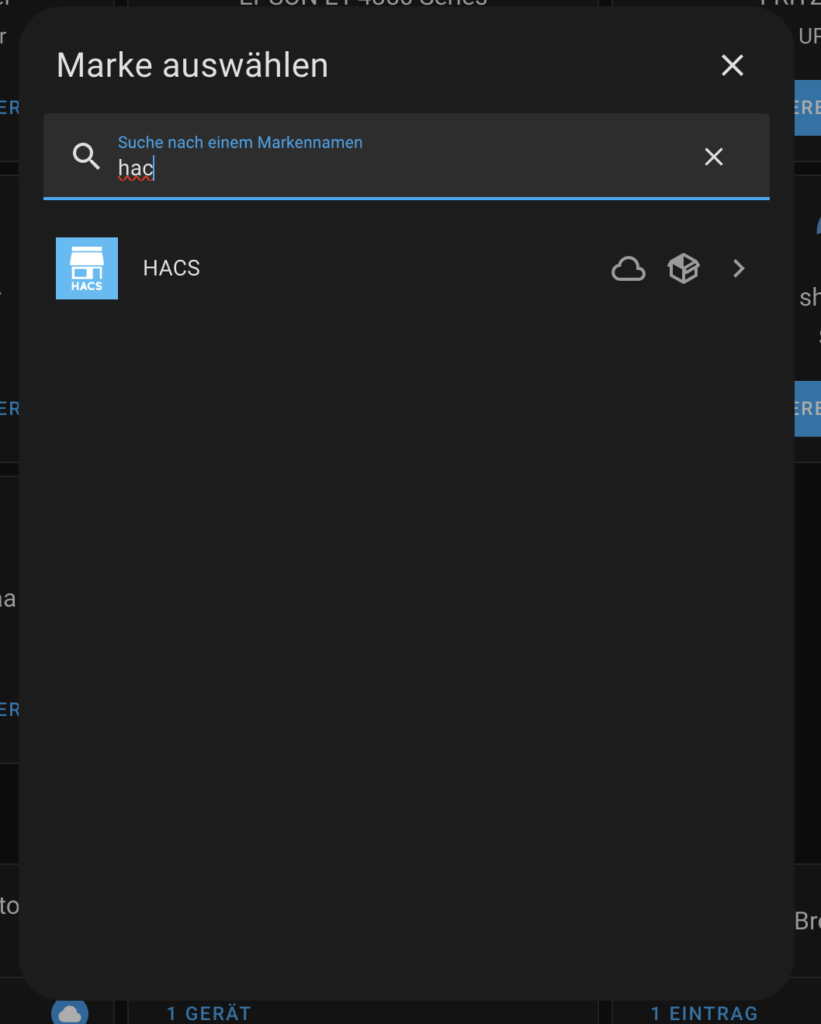
Dann kann man unter Einstellungen → Geräte und Dienste → Integration hinzufügen HACS hinzufügen.
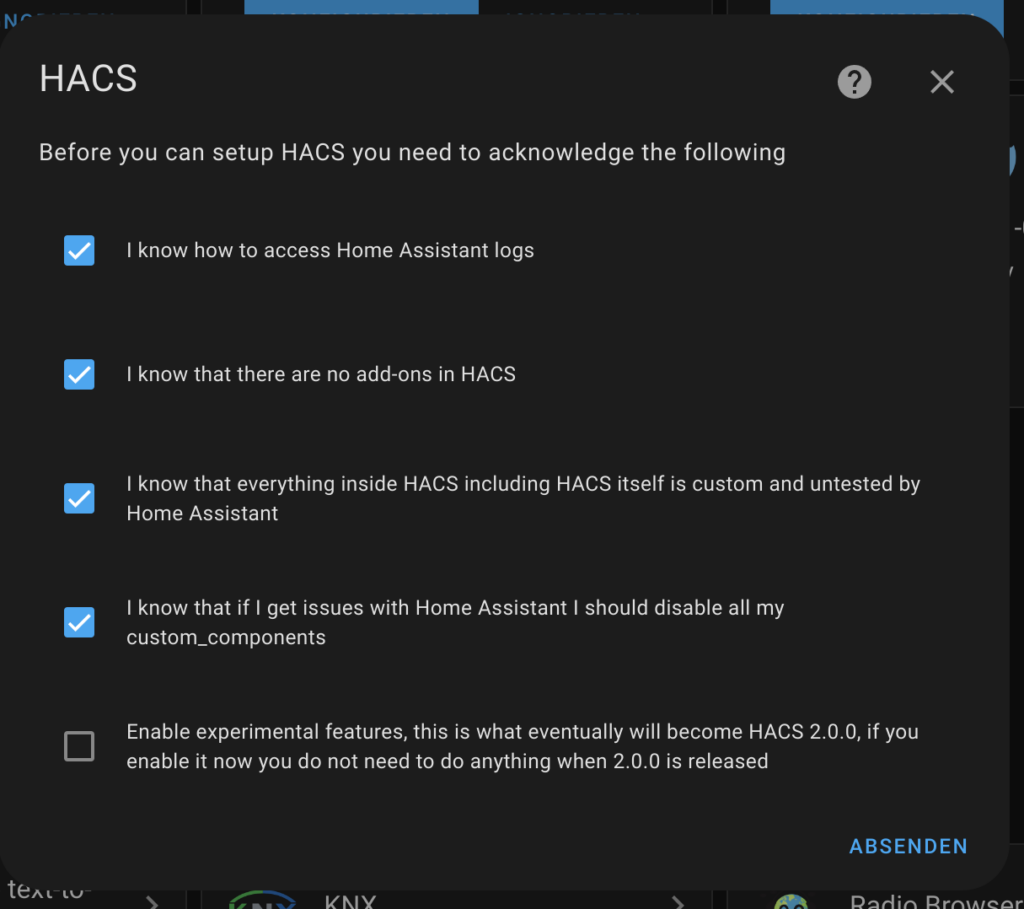
Nachdem man die Integration HACS gewählt hat, muss man noch einige Punkte bestätigen. Ich wähle alle außer den letzten. Anschließend muss man noch HACS mit seinem GitHub Account verbinden. Das ist nötig, da die Erweiterungen aus HACS von GitHub heruntergeladen werden.
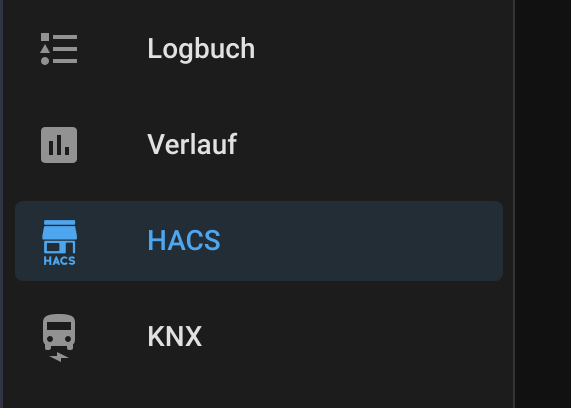
Hat man alles fertig eingerichtet, findet man HACS im Menü von Homeassistant und hat nun noch viel mehr Möglichkeiten, Geräte einzubinden und sein Dashboard zu gestalten.
Seit gut drei Jahren betreibe ich einen RaspberryPi als Homeserver. Zunächst reichte dieser noch gut aus. Mit der Zeit wurde aber nicht nur die Zahl der Anwendungen, die auf dem Raspberry laufen, mehr, sondern auch die Leistungsanforderungen der Anwendungen selbst. Besonders meine ich damit die Influx Datenbank, die seit über drei Jahren jede Minuten um einen Datensatz der PV-Anlage größer wird. Die Datenbank braucht mittlerweile über 10 Minuten zum Starten. Auch diese Webseite braucht zum Laden deutlich länger, als sie sollte. Wenn ich den Raspberry komplett neu starte, braucht es ca. eine Stunde, bis alle Anwendungen wieder laufen. Das ist definitiv zu viel. Es sollte also ein neuer Rechner her. In dieser Artikelserie möchte ich davon berichten.
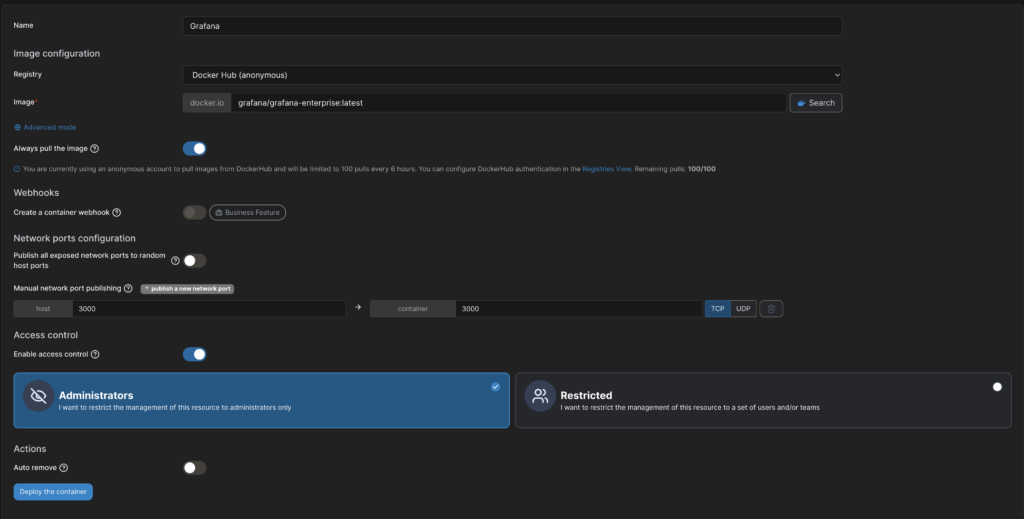
Grafana installiere ich als Docker-Container. Dazu lege ich in Portainer einen neuen Container an und wähle das Image „grafana/grafana-enterprise:latest“. Dann gebe ich noch den Port 3000 frei und lege ein Volume an.
Nachdem man den Container erstellt hat, gelangt man mit http://IP_ADRESSE:3000 auf die Weboberfläche von Grafana. Dort muss man noch ein Passwort festlegen, dann ist Grafana einsatzbereit.
InfluxDB in Grafana konfigurieren
Ich gehe davon aus, dass in InfluxDB bereits eine Datenbank angelegt ist. Diese wollen wir nun in Grafana einbinden.
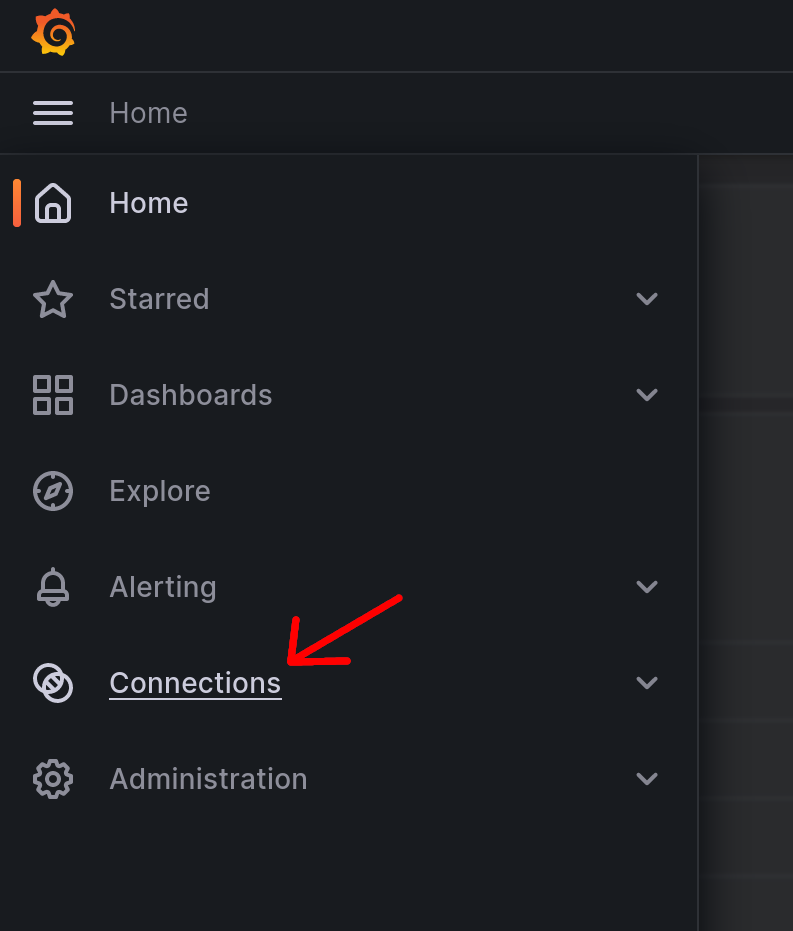
Dazu wähle ich im ausklappbaren Menü links den Punkt „Connections“
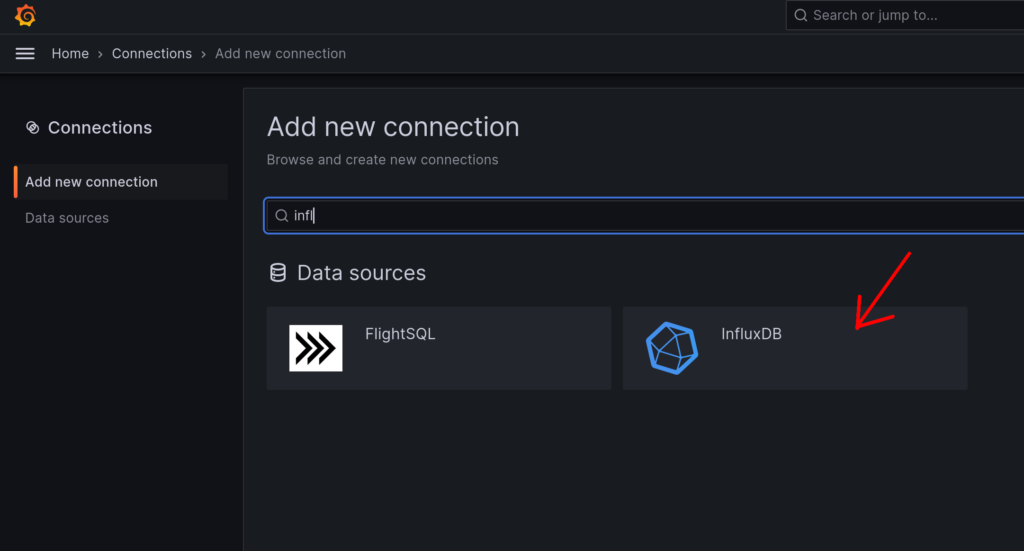
Anschließend wähle ich unter „Add new Connection“ die InfluxDB.
Dort klicke ich noch auf „Add new data source“.
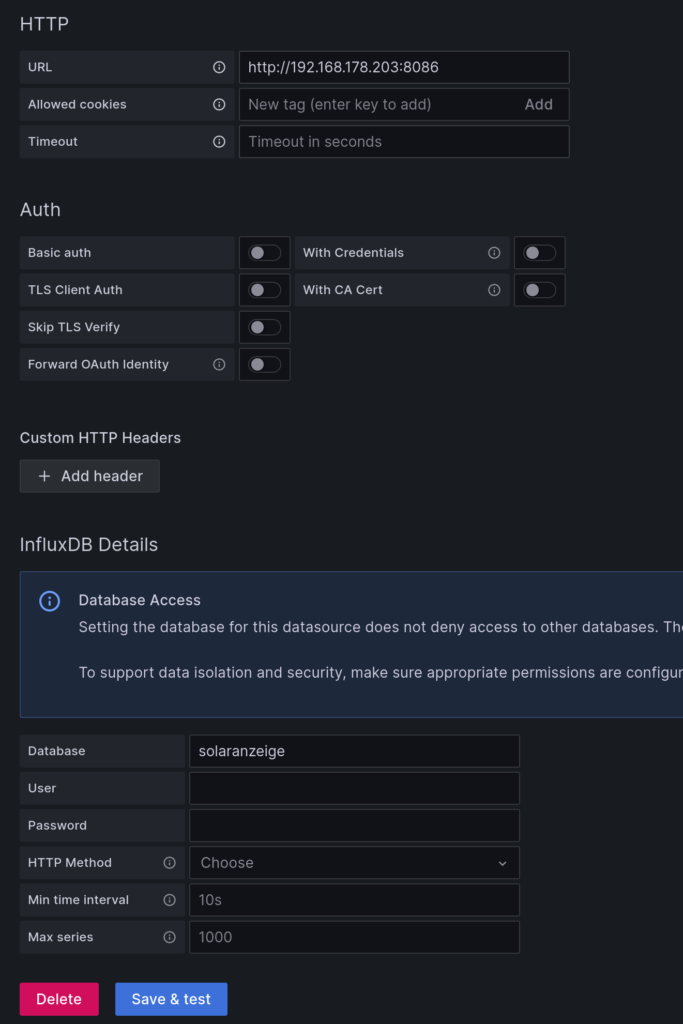
Anschließend lässt sich die Verbindung zur Datenbank konfigurieren. Als URL muss die IP-Adresse des Servers eingetragen werden. Standard-Port ist 8086. „localhost“ funktioniert hier nicht, weil „localhost“ auf die IP-Adresse des Docker-Containers zeigt, da wir Grafana ja über Docker installiert haben.
Im unteren Abschnitt muss noch der Name der Datenbank und falls vorhanden der Benutzername und das Passwort eingetragen werden.
Nach einem Klick auf „Save & test“ erhält man ein „datasource is working“ wenn alles funktioniert hat.
Fazit
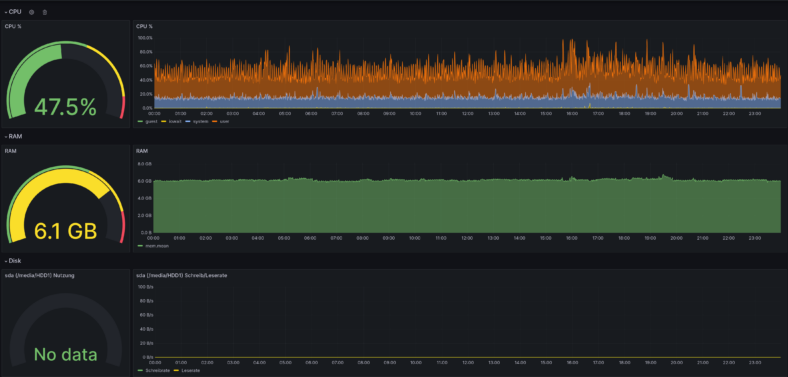
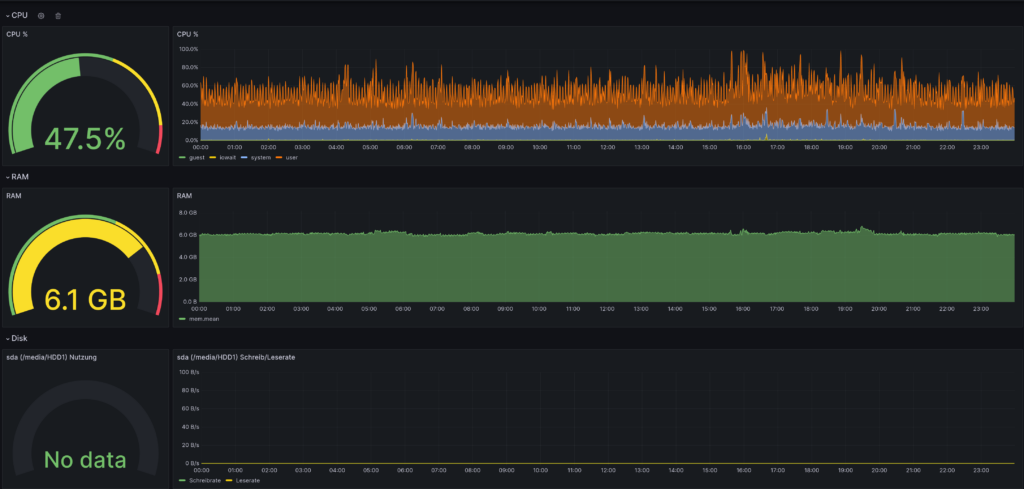
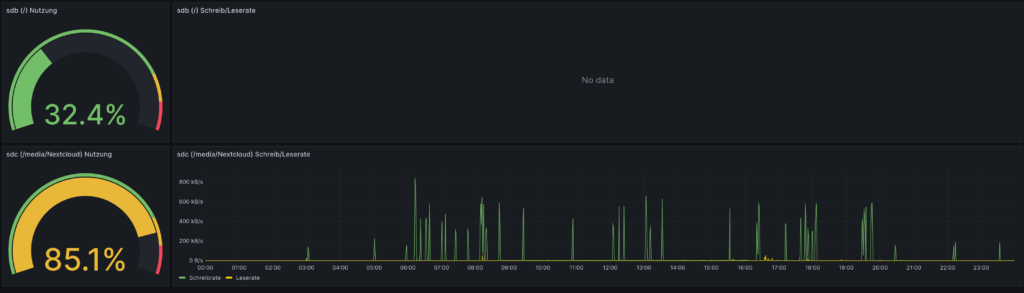
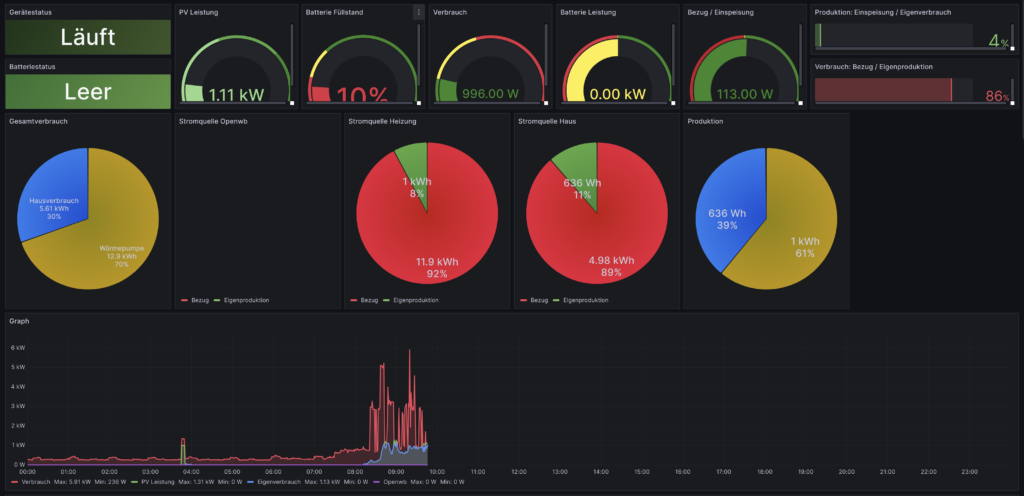
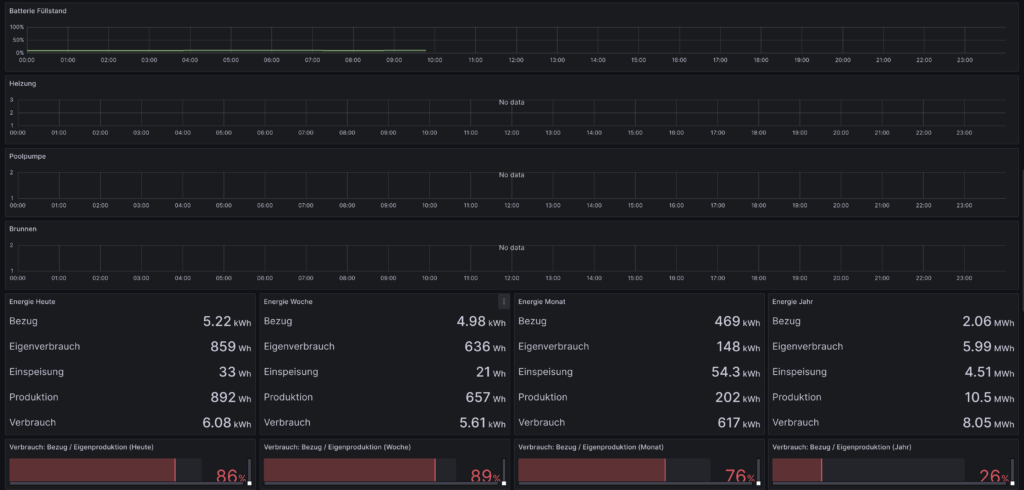
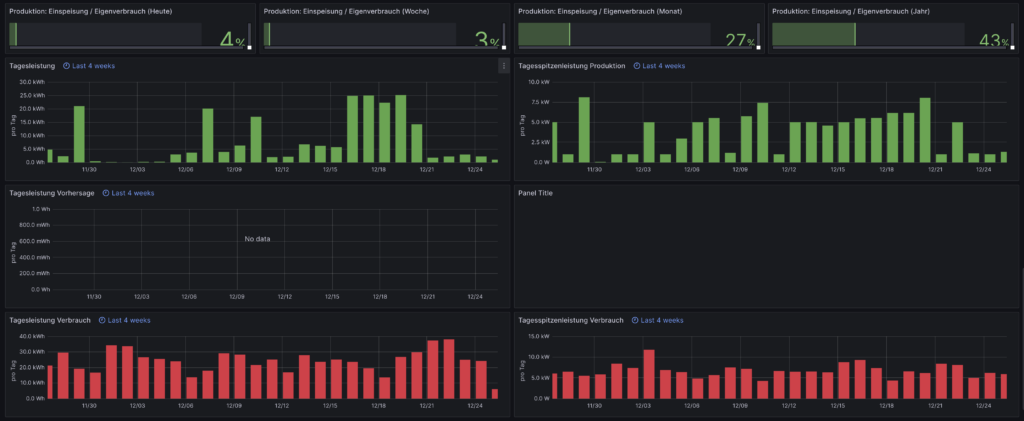
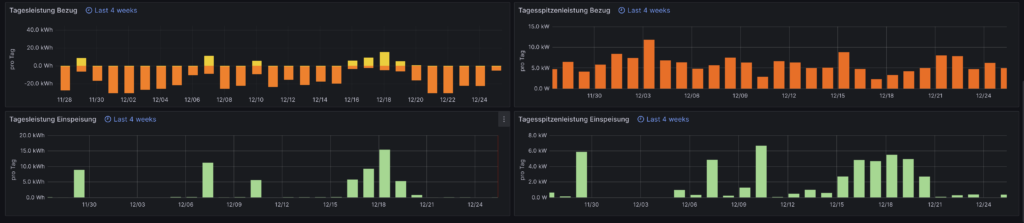
Auf das Erstellen eines Dashboards gehe ich hier nicht weiter ein, da das abhängig von der Art der Daten sehr unterschiedlich sein kann. Als Inspiration zeige ich hier noch zwei meiner Dashboards.
Seit gut drei Jahren betreibe ich einen RaspberryPi als Homeserver. Zunächst reichte dieser noch gut aus. Mit der Zeit wurde aber nicht nur die Zahl der Anwendungen, die auf dem Raspberry laufen, mehr, sondern auch die Leistungsanforderungen der Anwendungen selbst. Besonders meine ich damit die Influx Datenbank, die seit über drei Jahren jede Minuten um einen Datensatz der PV-Anlage größer wird. Die Datenbank braucht mittlerweile über 10 Minuten zum Starten. Auch diese Webseite braucht zum Laden deutlich länger, als sie sollte. Wenn ich den Raspberry komplett neu starte, braucht es ca. eine Stunde, bis alle Anwendungen wieder laufen. Das ist definitiv zu viel. Es sollte also ein neuer Rechner her. In dieser Artikelserie möchte ich davon berichten.
Jellyfin ist eine Streamingsoftware für den eigenen Server. Mit Jellyfin lassen sich Filme und Musik, die auf der Festplatte des Servers liegen, bequem im eigenen Netzwerk streamen. Es erkennt auch automatisch die Medien und fügt Informationen wie Cover, Erscheinungsjahr oder FSK-Freigabe hinzu. Kennt das Endgerät das Format der Medien nicht, konvertiert Jellyfin diese in Echtzeit um.
Einbinden einer NFS Freigabe von Openmediavault
Wer Teil 3 dieser Serie gelesen hat, weiß, dass ich meine Festplatten mit Openmediavault verwalte. Für Jellyfin habe ich dazu eine NFS Freigabe konfiguriert. Diese binde ich nun in mein Ubuntu ein.
Zuerst muss der NFS Client installiert werden:
1
sudo apt install nfs-common
Anschließend erstellen wir den Mountpoint, also die Stelle im Dateisystem, an dem später das Laufwerk eingehängt werden soll.
1
sudo mkdir-p/mnt/Jellyfin
Mit dem folgenden Befehl lassen sich alle NFS Freigaben eines Rechners anzeigen. So sieht man, welchen Pfad diese haben.
1
showmount-eIP_DES_SERVERS
Jetzt können wir die Freigabe einmal testweise manuell einhängen:
1
sudo mount IP_ADRESSE_SES_SERVERS:/export/Jellyfin/mnt/Jellyfin/
Nachdem ich getestet habe, ob das Einhängen funktioniert hat, hänge ich die Freigabe wieder aus:
1
sudo umount/mnt/Jellyfin
Um die Freigabe bei Systemstart automatisch einzuhängen, braucht es einen Eintrag in der Datei /etc/fstab.
Nach dem Speichern mit Strg+O und Schließen mit Strg+X kannst du zum Testen entweder den Server neu starten oder nur mit folgendem Befehl alle Einträge in der fstab einhängen:
1
sudo mount-a
Installation von Jellyfin
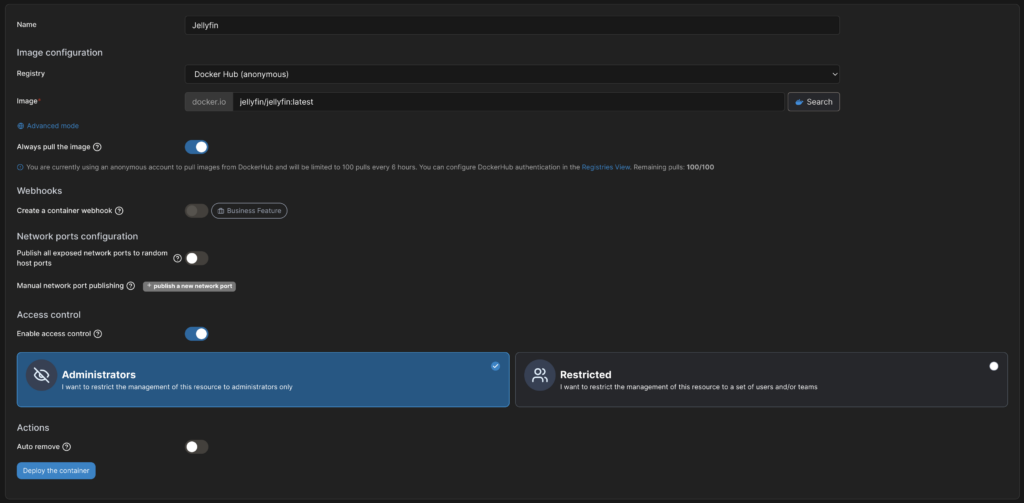
Ich installiere Jellyfin als Docker-Container. Also lege ich in Portainer einen neuen Container mit dem Namen „Jellyfin“ an und wähle das Image „jellyfin/jellyfin:latest“
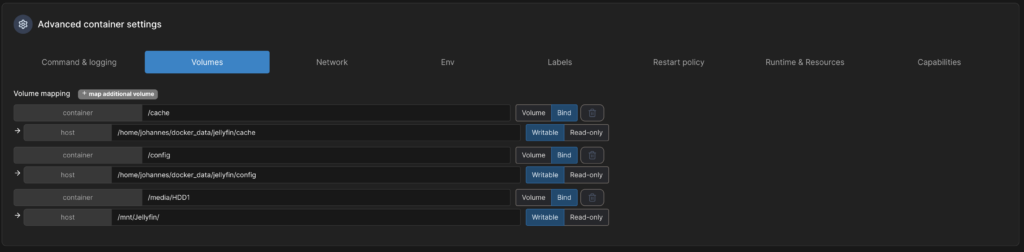
Im nächsten Schritt lege ich 3 Volumes an. Das letzte Volume ist der Mountpoint der Festplatte, auf der die Medien liegen.
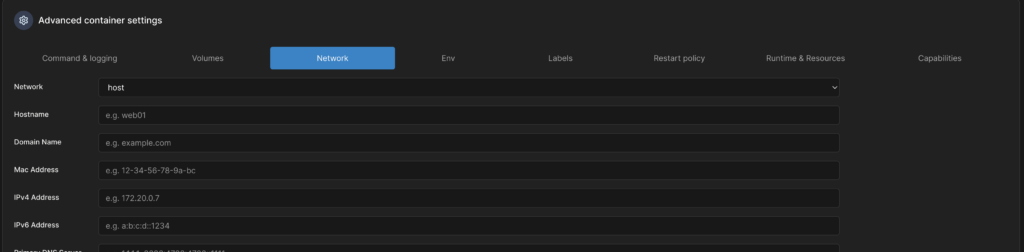
Im Menü „Network“ wähle ich abschließend noch „Host“ als Netzwerk aus.
Jetzt kann der Container erstellt werden. Die Weboberfläche von Jellyfin ist jetzt unter http://IP_DES_SERVERS:8096 erreichbar.
Einrichtung von Jellyfin
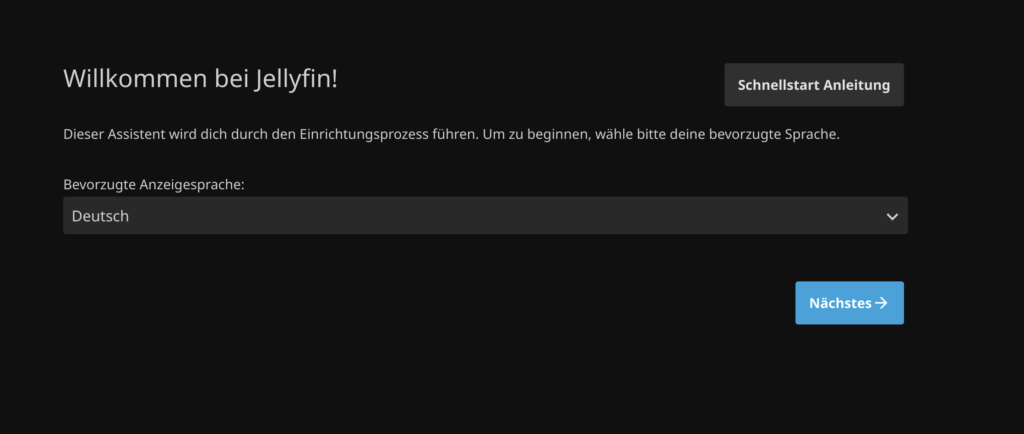
Unter dieser Adresse erreicht man direkt den Einrichtungsassistenten von Jellyfin. Als Sprache wähle ich Deutsch:
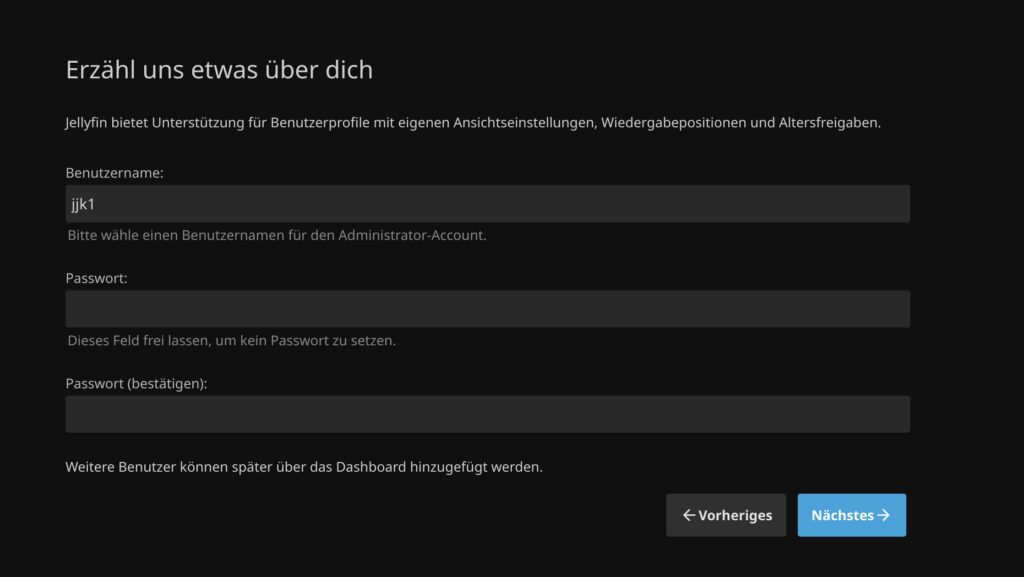
Anschließend muss man einen Benutzernamen und ein Passwort für das Admin-Konto festlegen:
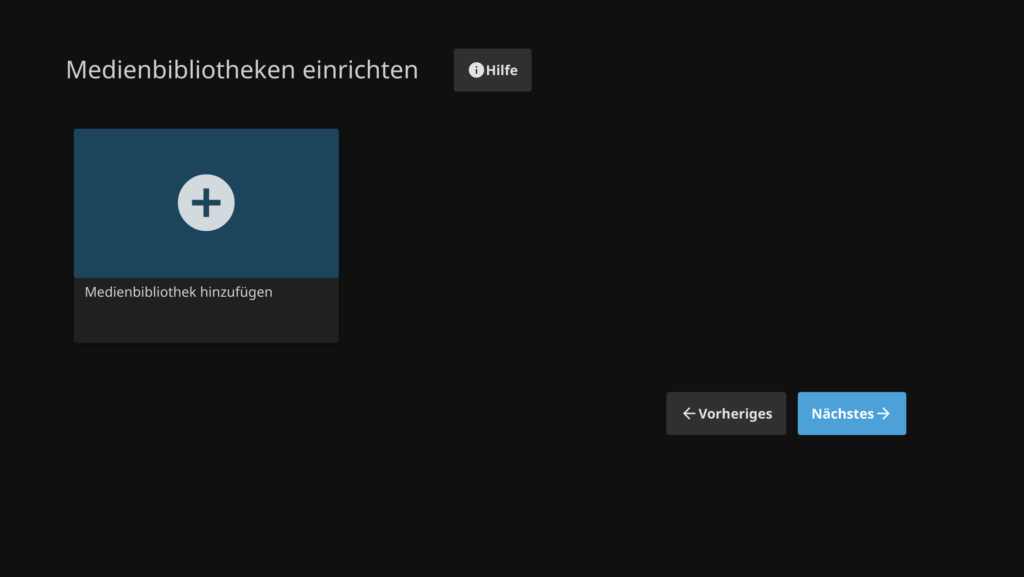
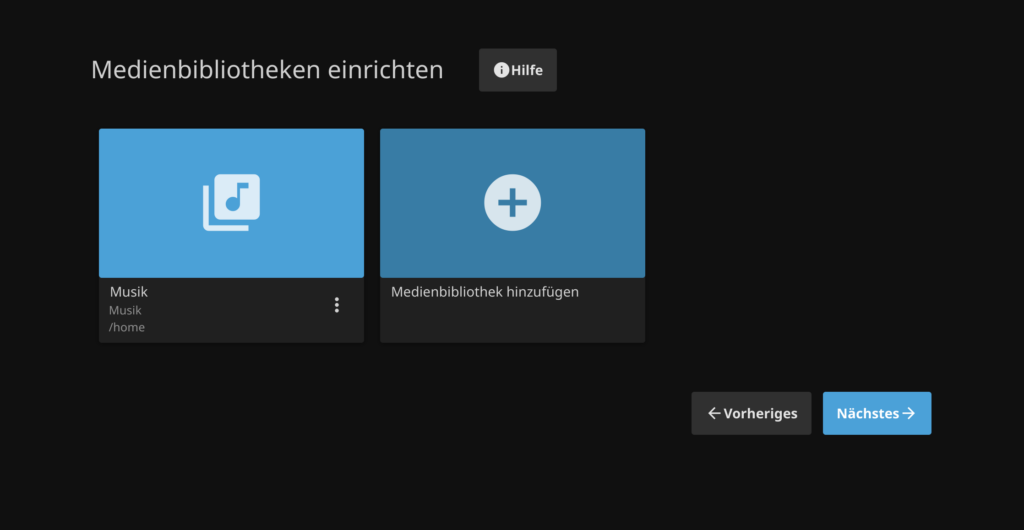
Im nächsten Schritt werden die Medienbibliotheken hinzugefügt. Ich erstelle zu Demonstrationszwecken eine Medienbibliothek für Musik.
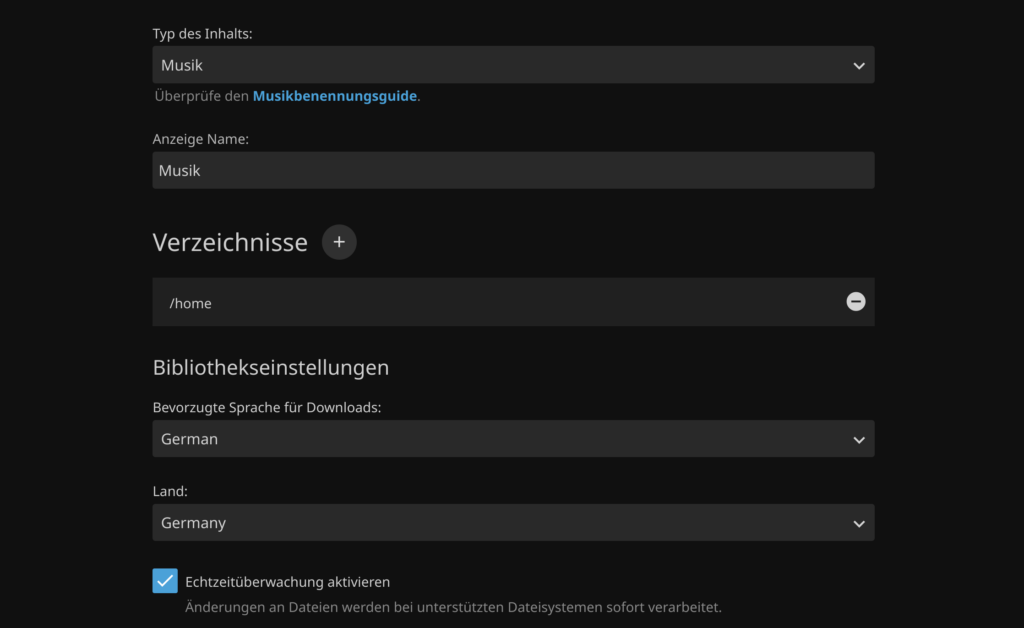
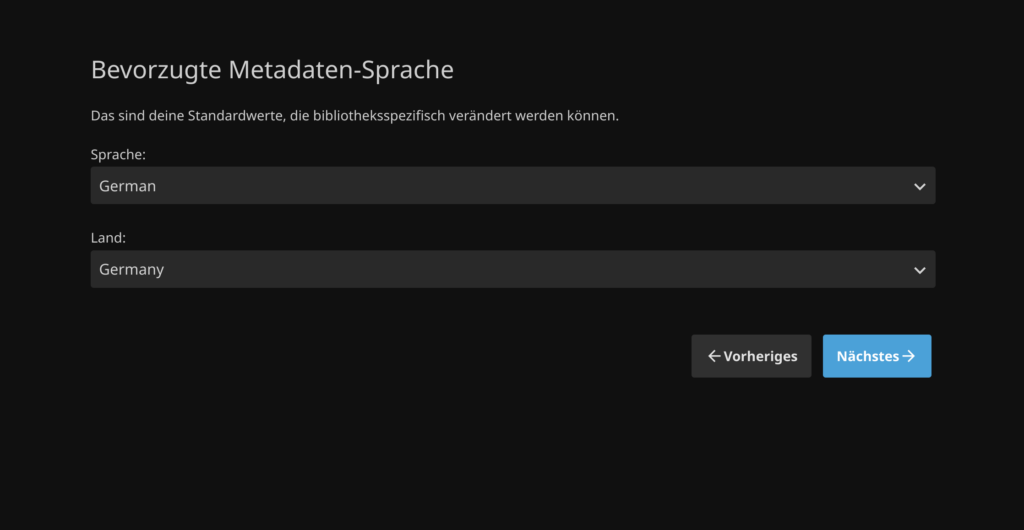
Als Typ des Inhalts wähle ich also Musik. Auch der Anzeigename bleibt bei „Musik“. Als Verzeichnisse müssen die Verzeichnisse ausgewählt werden, in denen die Musikdateien liegen. In meinem Beispiel oben habe ich meine Festplatte mit Medien in /media/HDD1 gemountet. Im Screenshot unten ist das aber nicht so, da es sich dabei nur um eine Testinstallation handelt. Als Sprache und Land wähle ich Deutsch/Deutschland und aktivieren anschließend die Echtzeitüberwachung. Das ist praktisch, da mit diesem Feature automatisch die Medien hinzugefügt werden, die man ins Medienverzeichnis kopiert.
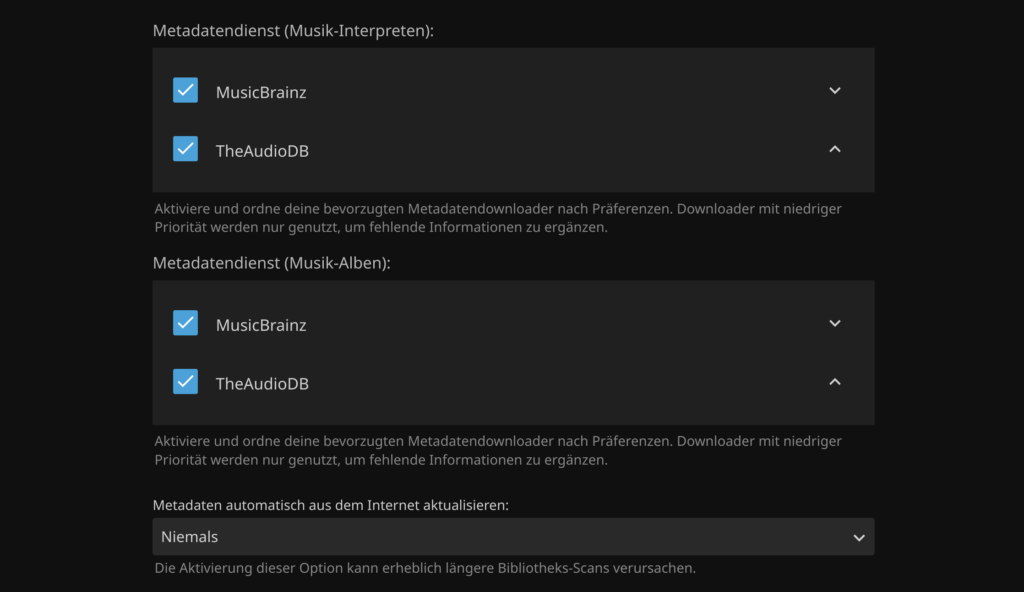
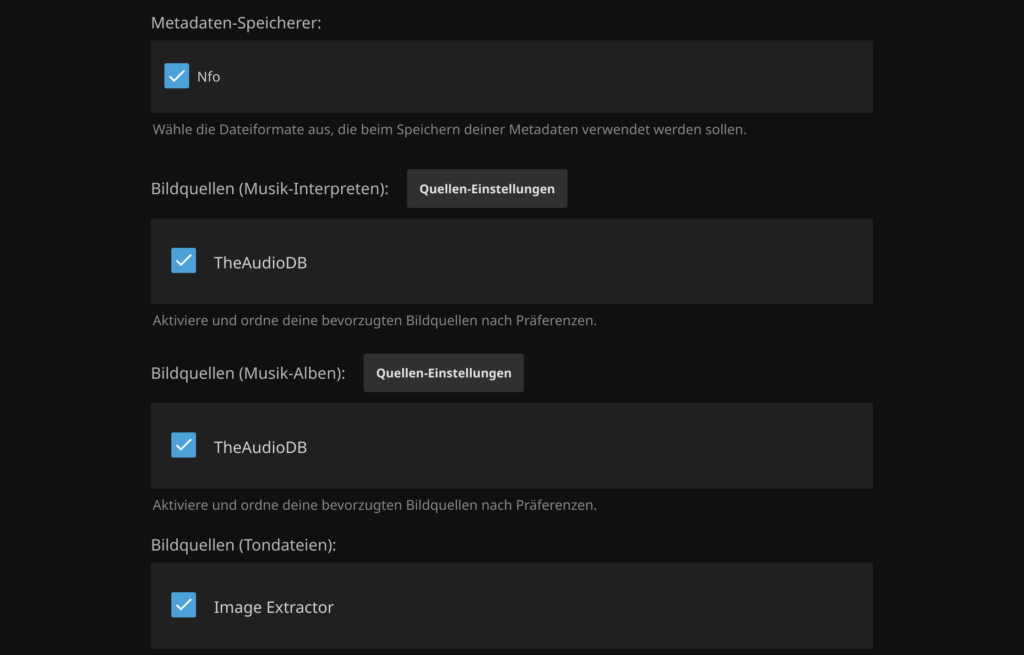
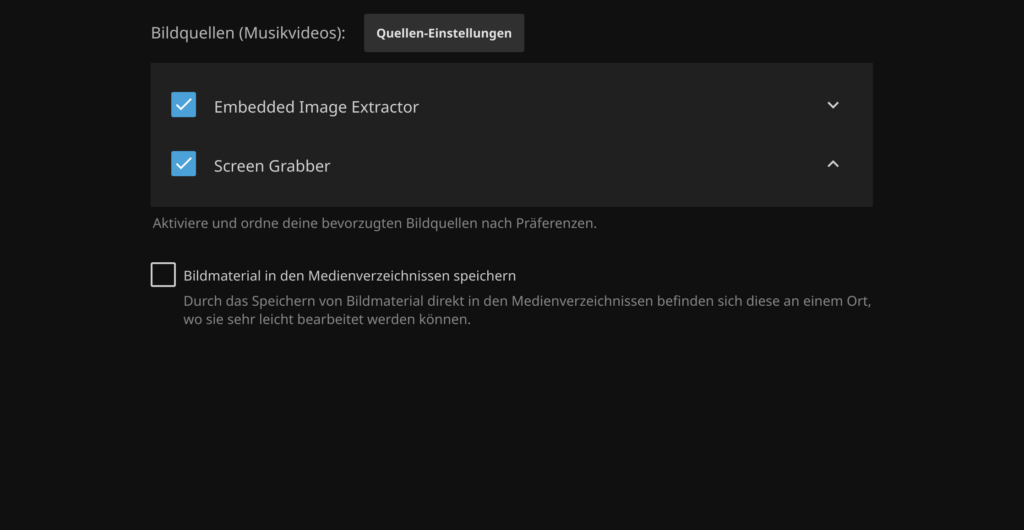
Bei den Diensten aktiviere ich grundsätzlich alle. Sowohl für Bildquellen, als auch für Metadaten.
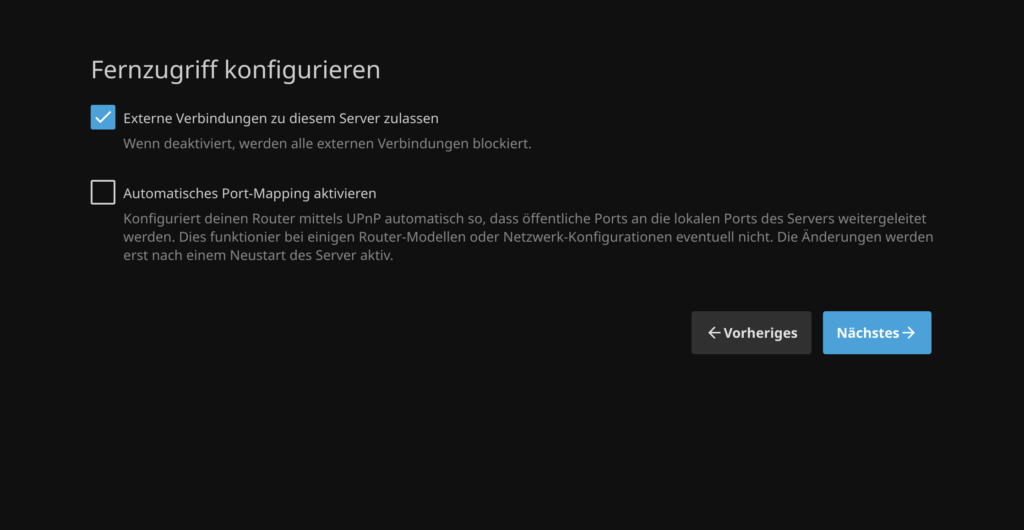
Anschließend könnte man noch weitere Bibliotheken, z. B. für Filme oder Serien einrichten. Das funktioniert sehr ähnlich. Ich belasse es jetzt aber bei meiner Musikbibliothek und klicke auf „Nächstes“.
Dort muss ich nochmal (wie oft habe ich jetzt schon Sprache und Land angegeben? 😅) Sprache und Land angeben, dieses Mal für die Metadaten. Im Abschnitt „Fernzugriff konfigurieren“ belasse ich alles auf Standardeinstellungen.
Sowohl die Benutzer- als auch die Administrationseinstellungen von Jellyfin erreicht man im Ausklappmenü link. Dort könnte man zum Beispiel die Bibliotheken bearbeiten.
Seit gut drei Jahren betreibe ich einen RaspberryPi als Homeserver. Zunächst reichte dieser noch gut aus. Mit der Zeit wurde aber nicht nur die Zahl der Anwendungen, die auf dem Raspberry laufen, mehr, sondern auch die Leistungsanforderungen der Anwendungen selbst. Besonders meine ich damit die Influx Datenbank, die seit über drei Jahren jede Minuten um einen Datensatz der PV-Anlage größer wird. Die Datenbank braucht mittlerweile über 10 Minuten zum Starten. Auch diese Webseite braucht zum Laden deutlich länger, als sie sollte. Wenn ich den Raspberry komplett neu starte, braucht es ca. eine Stunde, bis alle Anwendungen wieder laufen. Das ist definitiv zu viel. Es sollte also ein neuer Rechner her. In dieser Artikelserie möchte ich davon berichten.
Pihole ist ein Netzwerkweiter Blocker auf DNS-Ebene, unter anderem zum Blockieren von Werbung und Trackern
Vorbereitungen
Auf Ubuntu läuft standardmäßig ein DNS-Service auf Port 53. Das ist schlecht, denn auf Port 53 soll später unser Pihole laufen. Der Service lässt aber deaktivieren mit:
1
2
sudo systemctl stop systemd-resolved
sudo systemctl disable systemd-resolved
Jetzt ist unser Ubuntu aber ohne DNS-Server unterwegs, d. h., es ist nicht mehr dazu in der Lage Domains aufzulösen. Das lässt sich mit einem Eintrag in einer Datei beheben:
sudo nano /etc/resolv.conf
Dort ändern wir die Zeile nameserver 127.0.0.53 in nameserver 192.168.178.1 oder eben die IP-Adresse eines anderen DNS-Servers.
Ubuntu ist jetzt fertig für die Installation von Pihole.
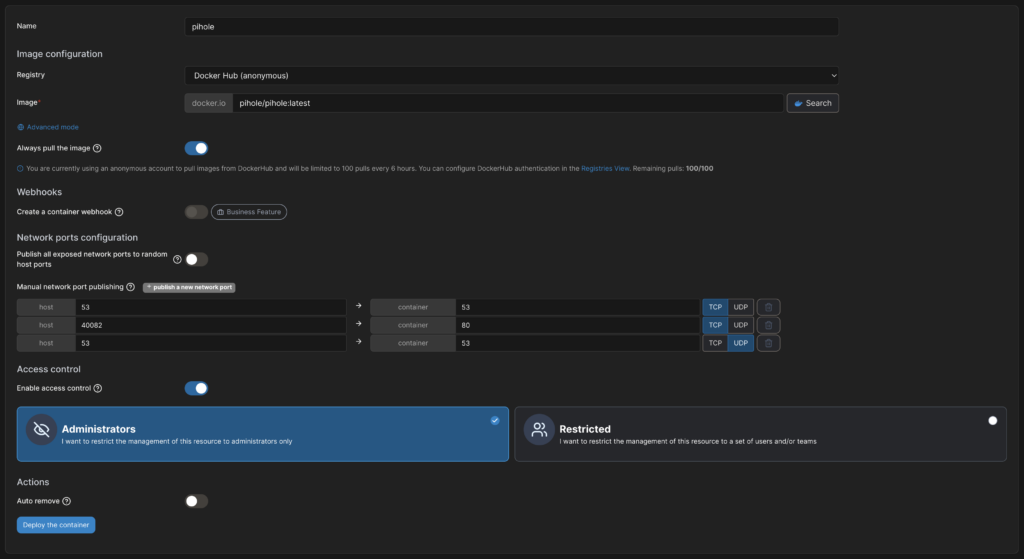
Installation von Pihole
Wir installieren wieder Pihole in einem Docker-Container. Dazu geben wir dem Container einen Namen, wählen das Image „pihole/pihole:latest“ und geben die Port 53 und 80 frei. Port 53 sowohl über TCP, als auch über UDP.
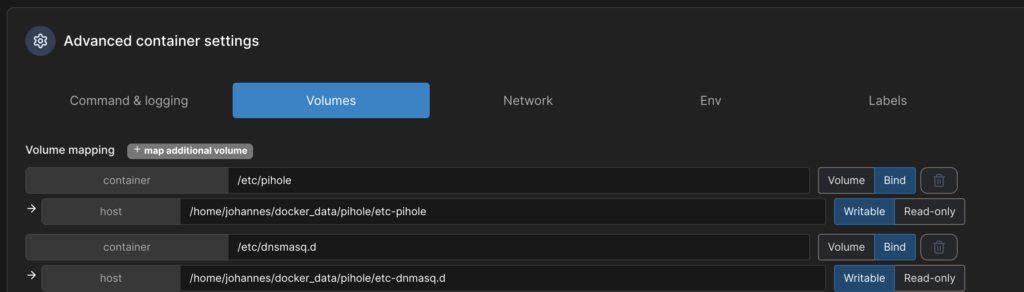
Dann legen wir 2 Volumes an:
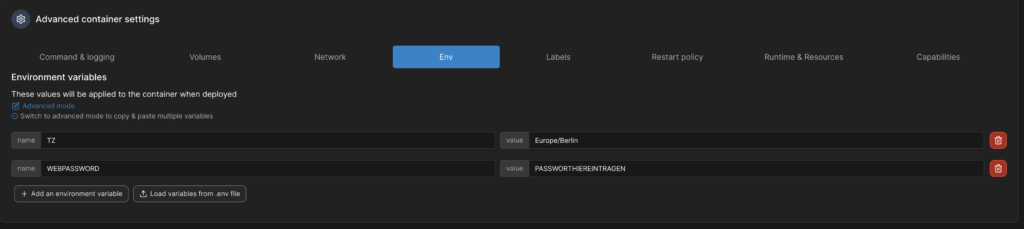
Und setzen über Environment Variablen die Zeitzone und das Passwort.
Der Pihole Container kann jetzt erstellt werden und ist dann unter dem gewählten Port mit /admin erreichbar, also: http://IP_ADRESSE:PORT/admin
Dort kann man jetzt Einstellungen vornehmen, wobei das erstmal nicht nötig ist. Pihole funktioniert auch schon auf Standardeinstellungen sehr gut.
Seit gut drei Jahren betreibe ich einen RaspberryPi als Homeserver. Zunächst reichte dieser noch gut aus. Mit der Zeit wurde aber nicht nur die Zahl der Anwendungen, die auf dem Raspberry laufen, mehr, sondern auch die Leistungsanforderungen der Anwendungen selbst. Besonders meine ich damit die Influx Datenbank, die seit über drei Jahren jede Minuten um einen Datensatz der PV-Anlage größer wird. Die Datenbank braucht mittlerweile über 10 Minuten zum Starten. Auch diese Webseite braucht zum Laden deutlich länger, als sie sollte. Wenn ich den Raspberry komplett neu starte, braucht es ca. eine Stunde, bis alle Anwendungen wieder laufen. Das ist definitiv zu viel. Es sollte also ein neuer Rechner her. In dieser Artikelserie möchte ich davon berichten.
Der Unifi Controller ist eine Software, die benötigt wird, um Unifi Geräte einzurichten. Man kann diese grundsätzlich auch nur temporär zur Einrichtung der Geräte auf seinem Rechner laufen lassen. Lässt man ihn aber 24/7 laufen, so erhält man einige interessante Statistiken.
Installation des Unifi Controllers
Bis vor kurzem war es noch möglich, den Unifi Controller mit einem einzigen Container zu installieren. Mittlerweile wurde aber die Datenbank ausgelagert. Man braucht also zwei Container. Einen für die Datenbank und einen für Unifi selbst.
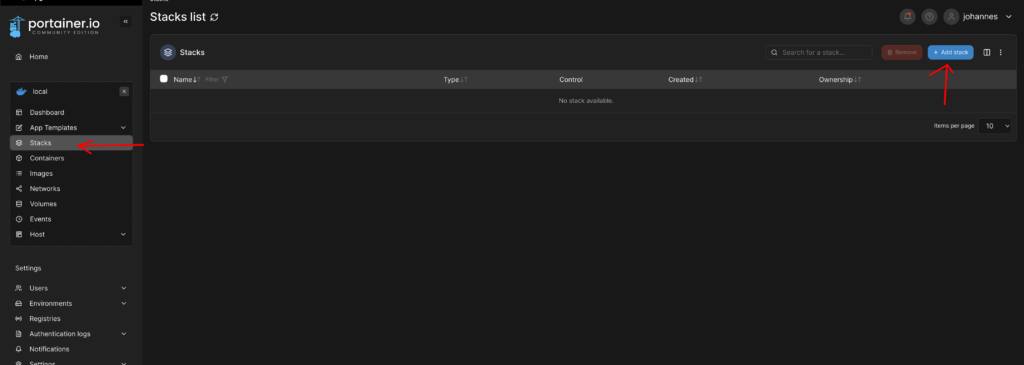
Dazu machen wir uns die Docker „Stacks“ zunutze. Ein Stack ist eine Einheit aus mehreren Containern (und Volumes).
Ich lege also einen neuen Stack in Portainer an:
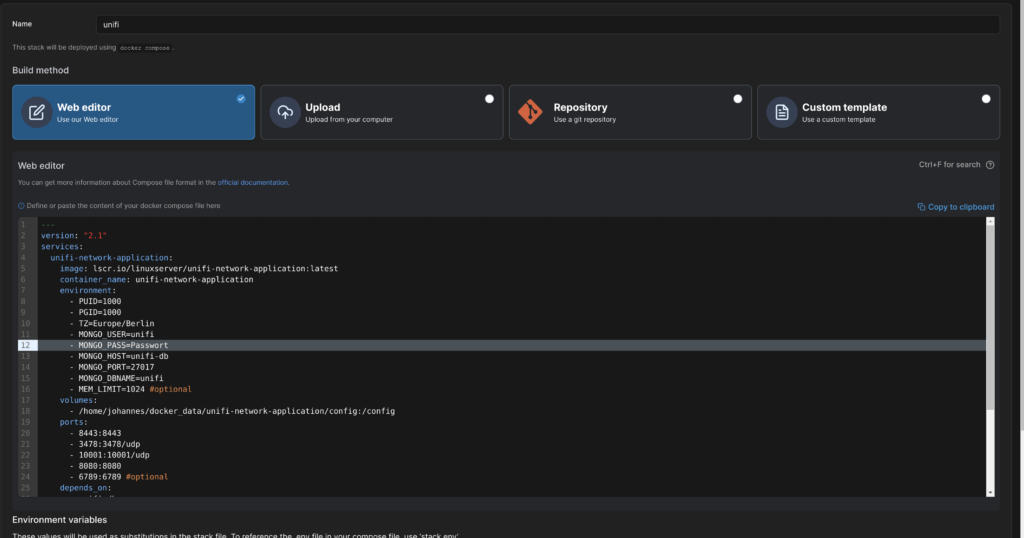
Diesem gebe ich einen Namen und füge folgenden Code im Webeditor ein.
Die Volumes musst du bei dir natürlich anpassen (nur den Teil vor dem Doppelpunkt). Ebenso das Passwort für die DB.
Anschließend klicke ich auf „Deploy this stack“, um den Unifi Controller samt Datenbank zu starten. Öffnet man jetzt die Weboberfläche des Unifi Controllers unter Port 8443, so erhält man ein „404 – Not found“. Das liegt daran, dass es in der Datenbank weder den Benutzer noch die Datenbank delbst gibt.
Konfiguration der Datenbank
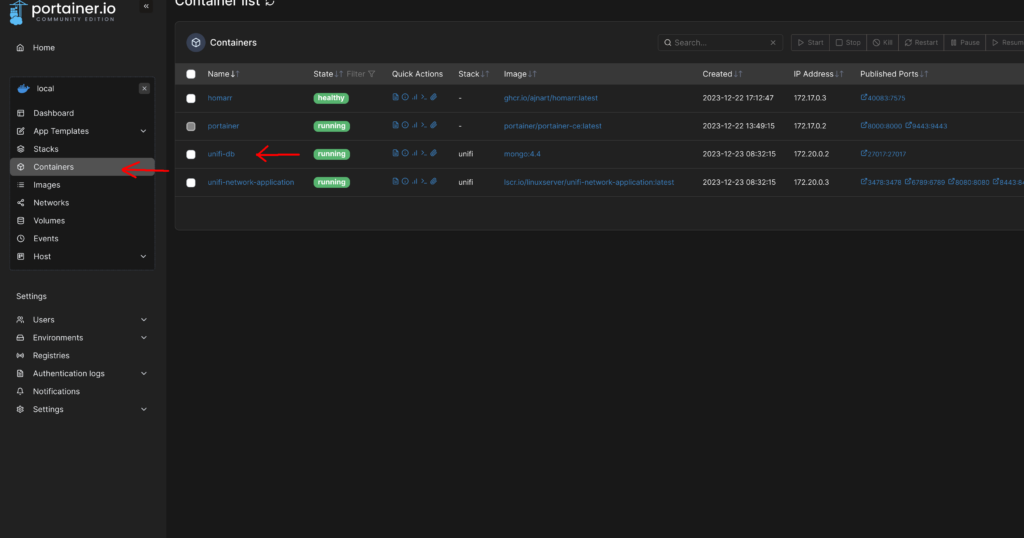
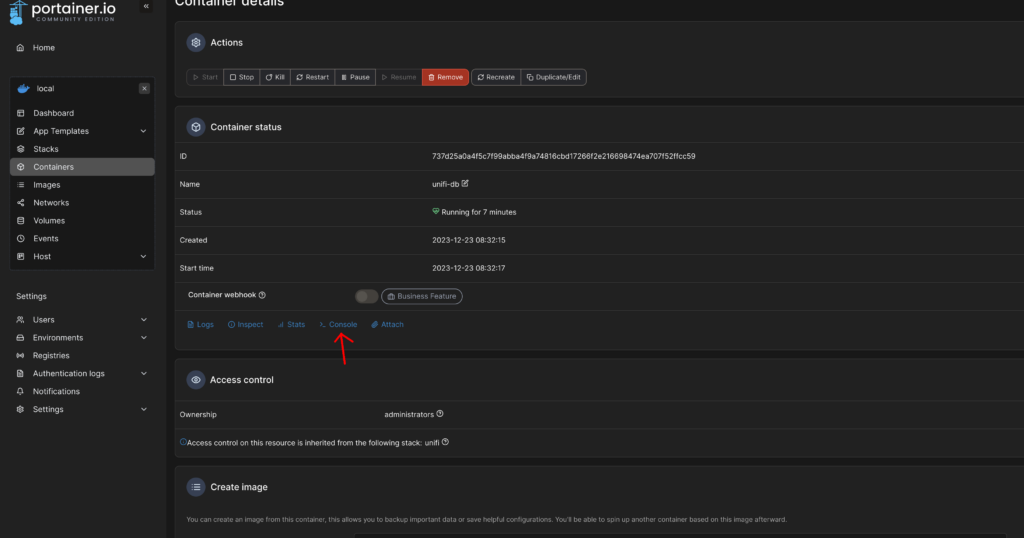
Um das zu ändern, wählen wir im Abschnitt „Containers“ unseren Container mit der Datenbank, in meinem Fall „unifi-db“.
Dort klicken wir auf „Console“ und anschließend auf „connect“.
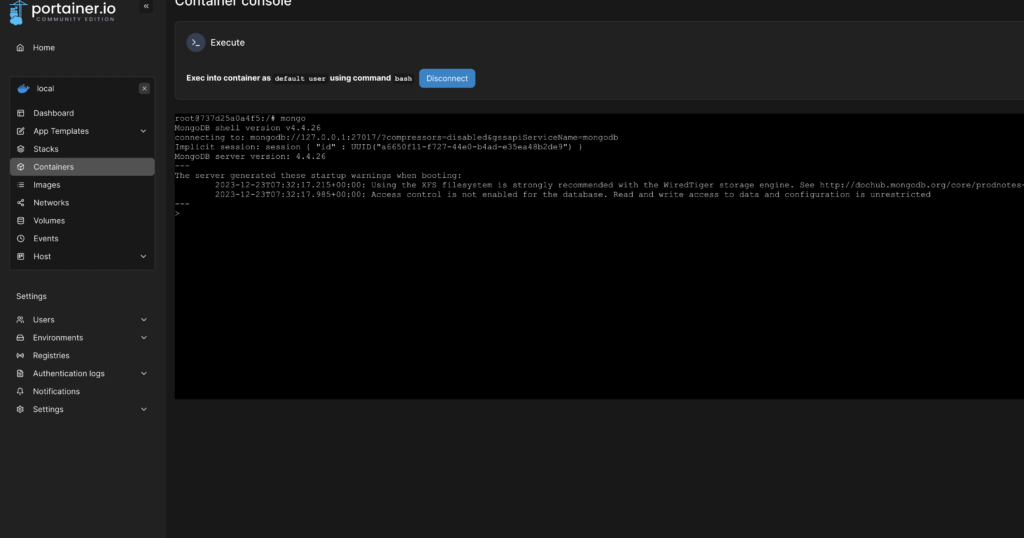
In der Konsole angekommen, geben wir mongo ein, um in die Konsole der Datenbank zu kommen.
Dort legen wir einen Benutzer und zwei Datenbanken mit den Befehlen:
Das Passwort muss natürlich wieder das gleiche sein, wie das Passwort, was wir bei der Installation vom Unifi Controller angegeben haben.
Unifi Controller konfigurieren
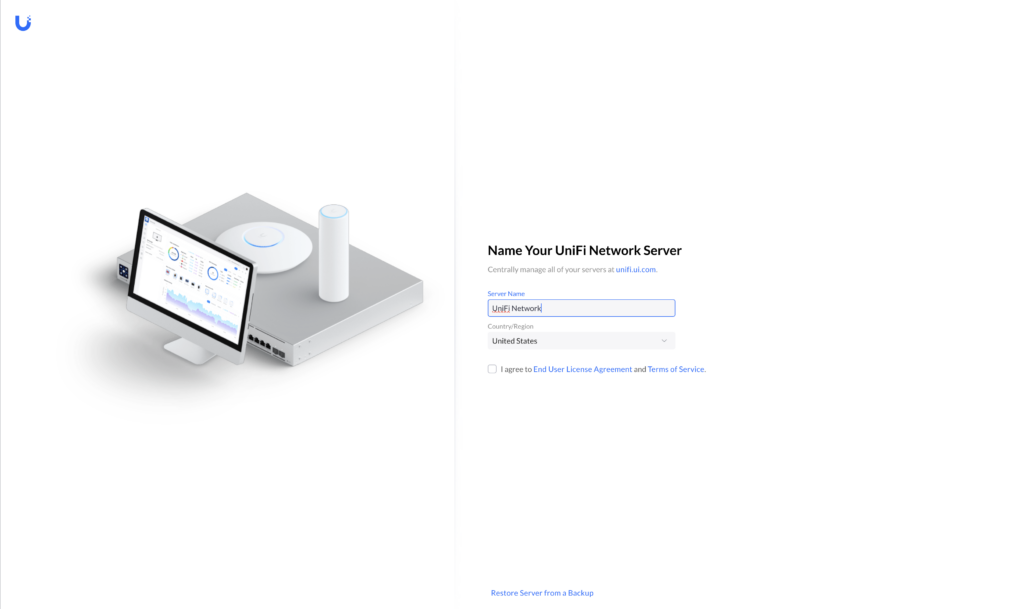
Jetzt sieht man unter der Adresse https://IP_ADRESSE:8443 den Einrichtungsassistenten von Unifi:
Da ich von einem anderen Server umziehe, wähle ich hier den Punkt „Restore Server from a Backup“ und werde hier nicht weiter auf die Einrichtung eingehen.
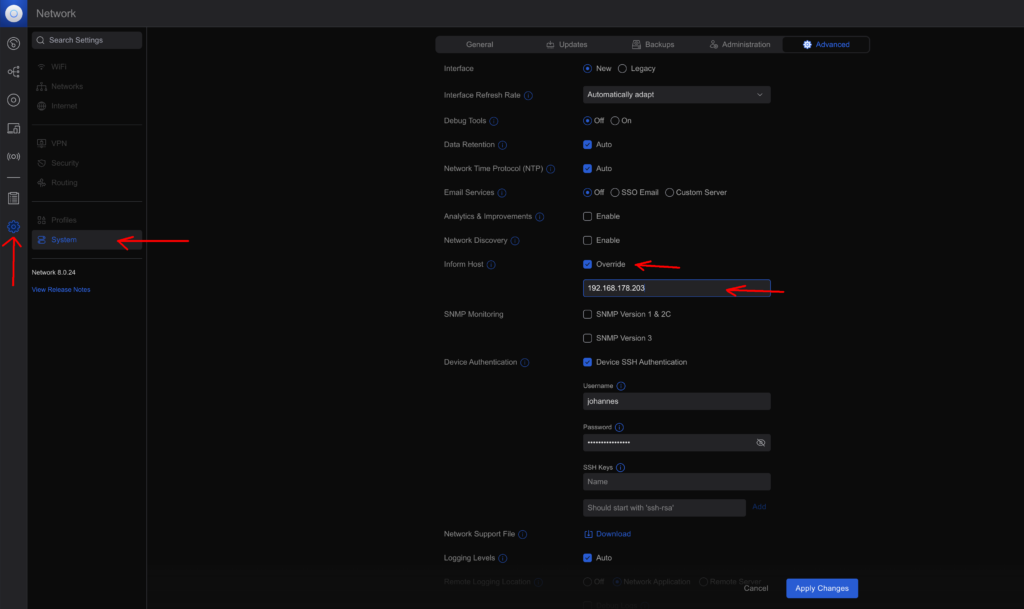
Ändern des Inform Host
Der Unifi Controller in Docker erkennt nicht von selbst, welche IP-Adresse er hat. Damit man Geräte hinzufügen kann, muss er dies aber wissen, damit er die Adresse den Geräten mitteilen kann.
In den Systemeinstellungen des Unifi Controllers kann man das festlegen:
Fazit
Der Unifi Controller ist jetzt fertig installiert und konfiguriert!